Monthly Archives: August 2023
Kompresi Citra dengan Metode Discrete Cosine Transform (DCT)
Discrete Cosine Transform (DCT) adalah teknik transformasi matematika yang digunakan untuk mengurangi redundansi dalam citra digital dan digunakan dalam kompresi citra. Berikut adalah langkah-langkah umum untuk melakukan kompresi citra menggunakan DCT:
- Membaca citra: Citra asli dibaca dan dipecah menjadi blok-blok kecil.
- Transformasi DCT: Setiap blok citra diubah menjadi domain frekuensi menggunakan transformasi DCT. DCT menghasilkan koefisien frekuensi yang merepresentasikan informasi dalam citra.
- Kuantisasi: Koefisien frekuensi yang dihasilkan oleh DCT dikuantisasi untuk mengurangi jumlah bit yang digunakan untuk merepresentasikan citra. Kuantisasi menghilangkan informasi yang tidak signifikan dalam citra.
- Kompresi: Kuantisasi menghasilkan koefisien frekuensi yang lebih kecil. Koefisien frekuensi yang kecil ini dihapus atau diubah menjadi nol untuk mengurangi ukuran data.
- Rekonstruksi: Citra dikembalikan ke domain spasial dari domain frekuensi menggunakan transformasi invers DCT.
Kompresi Citra Digital Menggunakan Transformasi Wavelet
Transformasi wavelet adalah teknik matematika yang digunakan untuk menganalisis dan merepresentasikan data dalam domain frekuensi dan waktu secara bersamaan. Berikut adalah beberapa poin penting tentang transformasi wavelet:
- Wavelet: Wavelet adalah fungsi matematika yang digunakan dalam transformasi wavelet. Fungsi ini memiliki sifat lokal dan dapat merepresentasikan perubahan dalam waktu dan frekuensi. Beberapa jenis wavelet yang umum digunakan termasuk Haar, Daubechies, Symlets, dan Coiflets.
- Multi-resolusi: Transformasi wavelet memungkinkan analisis data dalam berbagai resolusi. Dengan menggunakan skala yang berbeda, transformasi wavelet dapat mengungkapkan detail halus dan kasar dalam data.
- Dekomposisi: Transformasi wavelet dapat memecah data menjadi komponen frekuensi yang berbeda. Proses ini melibatkan dekomposisi data menjadi aproksimasi (komponen rendah frekuensi) dan detail (komponen tinggi frekuensi) menggunakan filter wavelet.
- Rekonstruksi: Rekonstruksi adalah proses menggabungkan komponen frekuensi yang telah dipecah menjadi bentuk aslinya menggunakan filter wavelet yang berlawanan.
- Aplikasi: Transformasi wavelet memiliki berbagai aplikasi dalam pengolahan sinyal dan citra, termasuk kompresi citra, pengenalan pola, denoising, deteksi tepi, dan analisis data time series.
Pengenalan Wajah Menggunakan Algoritma Principal Component Analysis (PCA)
Principal Component Analysis (PCA) adalah teknik analisis statistik yang digunakan untuk mengurangi dimensi data. Berikut adalah beberapa konsep penting terkait PCA:

- Dimensi data: Dimensi data adalah jumlah variabel atau fitur dalam dataset. PCA digunakan untuk mengurangi dimensi data dengan memproyeksikan data ke dalam ruang dimensi yang lebih rendah.
- Komponen utama: Komponen utama adalah kombinasi linear dari variabel dalam dataset yang menjelaskan sebagian besar variasi dalam data. PCA mencari komponen utama dengan memaksimalkan varians data yang dijelaskan oleh setiap komponen.
- Varians: Varians adalah ukuran seberapa tersebar data dalam satu dimensi. PCA memilih komponen utama yang memiliki varians tertinggi untuk mempertahankan sebanyak mungkin informasi dalam data.
- Reduksi dimensi: PCA digunakan untuk reduksi dimensi data dengan memproyeksikan data ke dalam ruang dimensi yang lebih rendah. Proyeksi dilakukan dengan mencari kombinasi linear dari fitur yang memaksimalkan pemisahan antara kelas.
Pemrograman MATLAB untuk Pengolahan Citra Medis: Visualisasi 3D Citra Kepala MRI
DICOM (Digital Imaging and Communications in Medicine) adalah standar format untuk menyimpan dan mentransmisikan citra medis, termasuk citra MRI. Untuk merepresentasikan citra 3D MRI kepala menggunakan file DICOM, berikut adalah langkah-langkah umum yang dapat diikuti:
- Akuisisi citra: Citra MRI kepala diambil menggunakan mesin MRI dan disimpan dalam format DICOM.
- Baca file DICOM: File DICOM dibaca menggunakan perangkat lunak atau pustaka yang mendukung format DICOM.
- Rekonstruksi citra 3D: Citra 3D direkonstruksi dari serangkaian citra 2D yang diambil dari mesin MRI. Proses rekonstruksi dapat dilakukan dengan menggunakan perangkat lunak khusus atau algoritma.
- Visualisasi citra 3D: Citra 3D yang direkonstruksi dapat divisualisasikan menggunakan perangkat lunak khusus atau algoritma. Visualisasi dapat dilakukan dengan memutar, memperbesar, atau memotong citra 3D untuk memeriksa bagian-bagian tertentu dari kepala.
- Segmentasi citra: Teknik segmentasi dapat diterapkan pada citra 3D untuk mengidentifikasi dan mengisolasi struktur atau wilayah tertentu dalam kepala, seperti otak atau pembuluh darah.
- Pemrosesan lanjutan: Citra 3D dapat diproses lebih lanjut untuk aplikasi tertentu, seperti perencanaan bedah virtual, pengukuran kuantitatif, atau pencetakan model 3D.
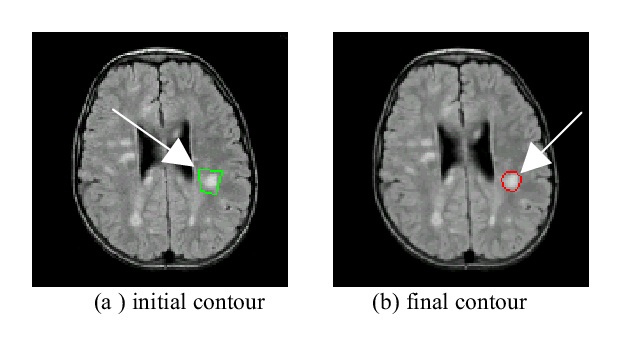
Segmentasi Citra Kepala MRI Menggunakan Metode Active Contour
Active Contour, juga dikenal sebagai Snakes, adalah teknik segmentasi citra yang digunakan untuk menemukan batas objek dalam citra. Berikut adalah beberapa konsep penting terkait Active Contour:
- Model Kontur Aktif: Model Kontur Aktif adalah model matematika yang digunakan untuk merepresentasikan kontur objek dalam citra. Model ini terdiri dari serangkaian titik yang dihubungkan oleh kurva. Kurva ini dapat bergerak dan menyesuaikan diri dengan batas objek dalam citra.
- Energi: Energi adalah fungsi matematika yang digunakan untuk mengukur seberapa baik kontur objek cocok dengan batas objek dalam citra. Energi terdiri dari dua bagian: energi internal dan energi eksternal. Energi internal digunakan untuk menjaga bentuk kontur tetap konsisten, sedangkan energi eksternal digunakan untuk menarik kontur ke arah batas objek dalam citra.
- Optimasi: Optimasi digunakan untuk menemukan kontur yang paling cocok dengan batas objek dalam citra. Optimasi dilakukan dengan meminimalkan energi model kontur aktif.
Klasifikasi Citra Daun Menggunakan Algoritma Jaringan Syaraf Tiruan Backpropagation
Jaringan Syaraf Tiruan Backpropagation adalah algoritma machine learning yang digunakan untuk klasifikasi dan regresi data. Berikut adalah beberapa konsep penting terkait dengan algoritma Jaringan Syaraf Tiruan Backpropagation:
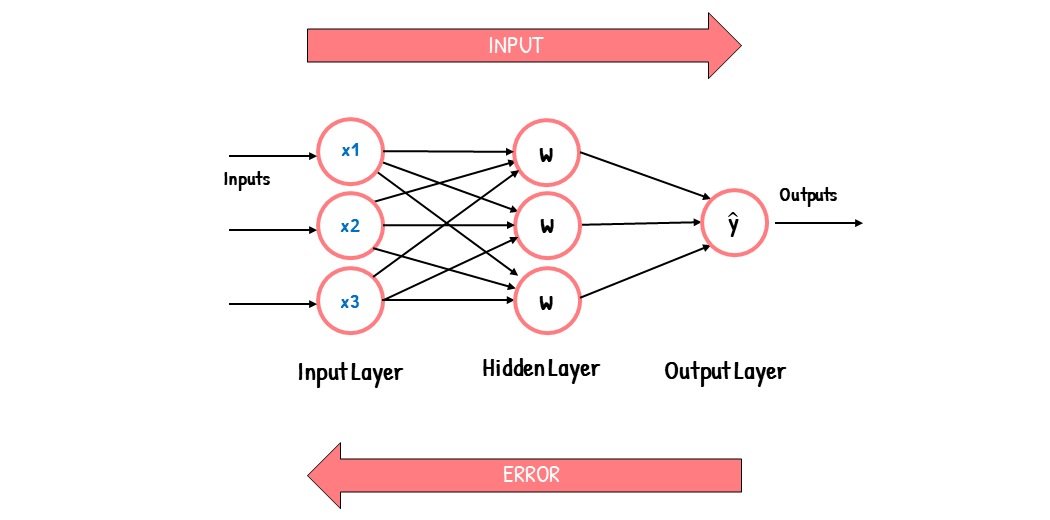
- Neuron buatan: Unit dasar jaringan syaraf tiruan adalah neuron buatan. Neuron buatan mewakili unit pemrosesan jaringan. Model neuron buatan yang diusulkan oleh McCulloch Pitts digunakan dalam aplikasi klasifikasi pola jaringan syaraf tiruan.
- Backpropagation: Backpropagation adalah metode pelatihan jaringan syaraf tiruan yang diawasi. Tujuan backpropagation adalah untuk memodifikasi bobot untuk melatih jaringan neural untuk memetakan input arbitrer ke output dengan benar. Perceptron berlapis-lapis dapat dilatih menggunakan algoritma backpropagasi.
- Arsitektur: Arsitektur jaringan syaraf tiruan backpropagation terdiri dari lapisan input, lapisan tersembunyi, dan lapisan output. Lapisan tersembunyi dapat memiliki beberapa lapisan tergantung pada kompleksitas masalah.
- Bobot: Bobot adalah parameter yang digunakan untuk menghubungkan neuron dalam jaringan syaraf tiruan. Bobot diatur selama pelatihan jaringan syaraf tiruan untuk meminimalkan kesalahan.
- Bias: Bias adalah parameter yang digunakan untuk menambahkan offset ke keluaran neuron. Bias juga diatur selama pelatihan jaringan syaraf tiruan untuk meminimalkan kesalahan.
Klasifikasi Citra Buah Apel Menggunakan Algoritma K-Nearest Neighbors (K-NN)
K-Nearest Neighbors (K-NN) adalah algoritma machine learning yang digunakan untuk klasifikasi dan regresi data. Berikut adalah beberapa konsep penting terkait K-NN:

- K-NN: K-NN mencari k titik data terdekat dari data yang akan diprediksi. K-NN kemudian memprediksi label atau nilai target dari data yang akan diprediksi berdasarkan mayoritas label atau nilai target dari k titik data terdekat.
- Jarak: K-NN menggunakan jarak Euclidean atau jarak Manhattan untuk mengukur jarak antara titik data.
- Kelas: K-NN digunakan untuk klasifikasi data. K-NN memprediksi label atau kelas dari data berdasarkan mayoritas label atau kelas dari k titik data terdekat.
- Regresi: K-NN juga dapat digunakan untuk regresi data. K-NN memprediksi nilai target dari data berdasarkan rata-rata nilai target dari k titik data terdekat.
Klasifikasi Citra Buah Menggunakan Algoritma Linear Discriminant Analysis (LDA)
Linear Discriminant Analysis (LDA) adalah algoritma pembelajaran mesin yang digunakan untuk klasifikasi dan reduksi dimensi data. Berikut adalah beberapa konsep penting terkait LDA:
- Teorema Bayes: LDA didasarkan pada teorema Bayes, yang digunakan untuk menghitung probabilitas kondisional. Teorema Bayes menyatakan bahwa probabilitas suatu hipotesis atau kelas tertentu, diberikan data yang diamati, dapat dihitung dari probabilitas data yang diamati, diberikan hipotesis atau kelas tertentu.
- Reduksi dimensi: LDA digunakan untuk mengurangi dimensi data dengan memproyeksikan data ke dalam ruang dimensi yang lebih rendah. Proyeksi dilakukan dengan mencari kombinasi linear dari fitur yang memaksimalkan pemisahan antara kelas.
- Klasifikasi: LDA juga dapat digunakan untuk klasifikasi data. Setelah dimensi data direduksi, LDA membangun model klasifikasi dengan menghitung probabilitas kondisional untuk setiap kelas.
- Canonical Discriminant Analysis (CDA): CDA adalah variasi dari LDA yang mencari sumbu (koordinat kanonik) yang terbaik memisahkan kelas-kelas data. Sumbu-sumbu ini tidak berkorelasi satu sama lain dan mendefinisikan ruang optimal yang memisahkan kelas-kelas data.
Klasifikasi Sayuran Menggunakan Algoritma Naive Bayes
Naive Bayes classifier adalah algoritma pembelajaran mesin yang digunakan untuk klasifikasi data. Berikut adalah beberapa konsep penting yang terkait dengan Naive Bayes classifier:
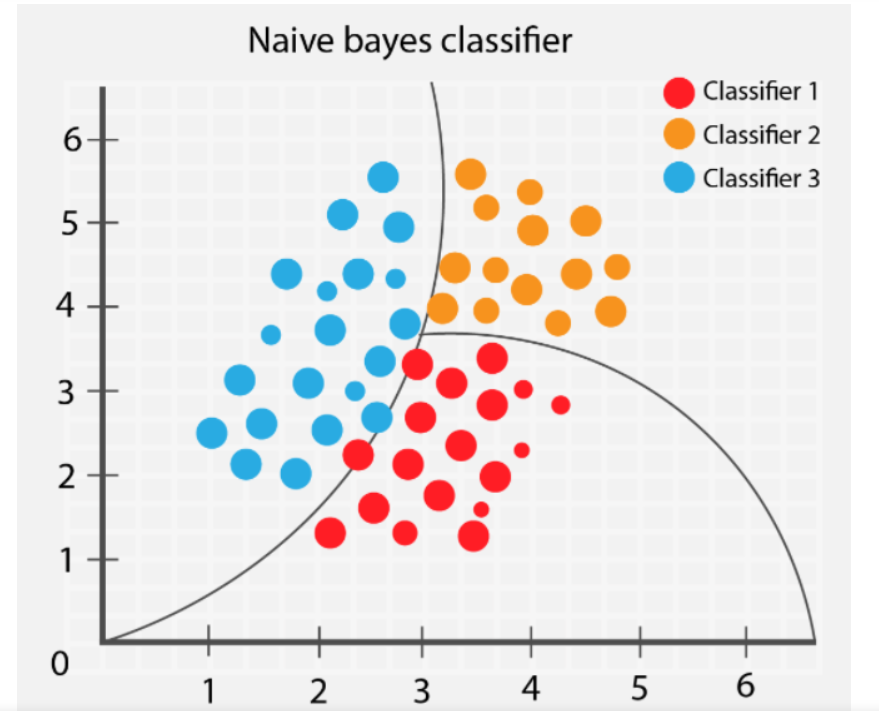
- Bayes’ Theorem: Naive Bayes classifier didasarkan pada teorema Bayes, yang digunakan untuk menghitung probabilitas kondisional. Teorema Bayes menyatakan bahwa probabilitas suatu hipotesis atau kelas tertentu, diberikan data yang diamati, dapat dihitung dari probabilitas data yang diamati, diberikan hipotesis atau kelas tertentu.
- Probabilitas kondisional: Probabilitas kondisional adalah probabilitas suatu kejadian terjadi, diberikan kejadian lain telah terjadi. Dalam Naive Bayes classifier, probabilitas kondisional digunakan untuk menghitung probabilitas suatu kelas, diberikan nilai fitur dari data.
- Fitur: Fitur adalah variabel yang digunakan untuk menggambarkan data. Dalam Naive Bayes classifier, fitur digunakan untuk memprediksi kelas dari data.
- Kelas: Kelas adalah label atau kategori yang diberikan pada data. Dalam Naive Bayes classifier, kelas digunakan untuk memprediksi label atau kategori dari data.
- Naive Bayes Assumption: Naive Bayes classifier mengasumsikan bahwa semua fitur dalam data adalah independen satu sama lain. Meskipun asumsi ini sering kali tidak benar dalam dunia nyata, Naive Bayes classifier tetap efektif dalam banyak kasus.
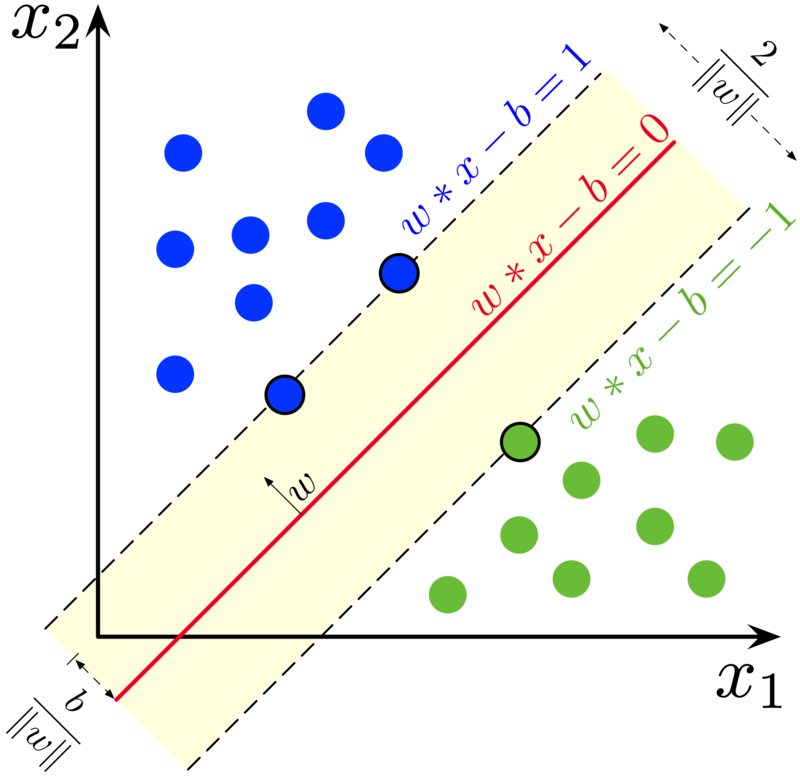
Klasifikasi Bunga Menggunakan Algoritma Support Vector Machine (SVM)
Support Vector Machine (SVM) adalah salah satu algoritma pembelajaran mesin yang digunakan untuk klasifikasi dan regresi data. SVM bekerja dengan membangun hyperplane atau serangkaian hyperplane di ruang dimensi tinggi atau tak terbatas, yang dapat digunakan untuk klasifikasi, regresi, atau tugas lain seperti deteksi outlier. SVM memilih titik-titik ekstrim atau vektor yang membantu dalam membuat hyperplane. Titik-titik ekstrim ini disebut sebagai support vector, dan oleh karena itu algoritma ini disebut sebagai Support Vector Machine. SVM dapat digunakan untuk berbagai tugas seperti klasifikasi teks, klasifikasi gambar, deteksi spam, identifikasi tulisan tangan, analisis ekspresi gen, deteksi wajah, dan deteksi anomali.