
k-means Clustering
Data clustering merupakan salah satu metode data mining yang bersifat tanpa arahan (unsupervised).
Ada dua jenis data clustering yang sering digunakan dalam proses pengelompokan data yaitu hierarchical (hirarki) data clustering dan non-hierarchical (non hirarki) data clustering.
K-means merupakan salah satu metode data clustering non hirarki yang berusaha mempartisi data yang ada ke dalam satu atau lebih cluster/kelompok.
Metode ini mempartisi data ke dalam cluster/kelompok sehingga data yang memiliki karakteristik yang sama dikelompokkan ke dalam satu cluster yang sama dan data yang mempunyai karakteristik yang berbeda dikelompokkan ke dalam kelompok yang lain.
Ilustrasi algoritma k-means ditunjukkan pada gambar di bawah ini:

Algoritma untuk melakukan k-means clustering adalah sebagai berikut:
1. Tentukan jumlah kluster yang diinginkan (k)
2. Tentukan nilai centroids awal secara acak
3. Hitung jarak tiap data terhadap masing-masing centroid
4. Kelompokkan data-data tersebut ke kluster berdasarkan jarak paling dekat (minimum) terhadap sebuah kluster
5. Hitung ulang nilai centroids dengan menghitung nilai rerata (mean) data dari masing-masing kluster
6. Lakukan langkah 3-5 hingga nilai centroids tidak lagi mengalami perubahan
Perhitungan jarak antara centroid dengan data dapat dilakukan menggunakan persamaan euclidean distance, cityblock, cosine, correlation, maupun hamming.
Berikut ini merupakan contoh aplikasi pemrograman matlab untuk melakukan teknik clustering pada pengenalan pola citra.
Pada contoh ini algoritma k-means digunakan untuk mengkluster 60 citra yang terdiri dari 20 citra kelelawar, 20 citra ikan, dan 20 citra katak seperti ditunjukkan pada gambar berikut:
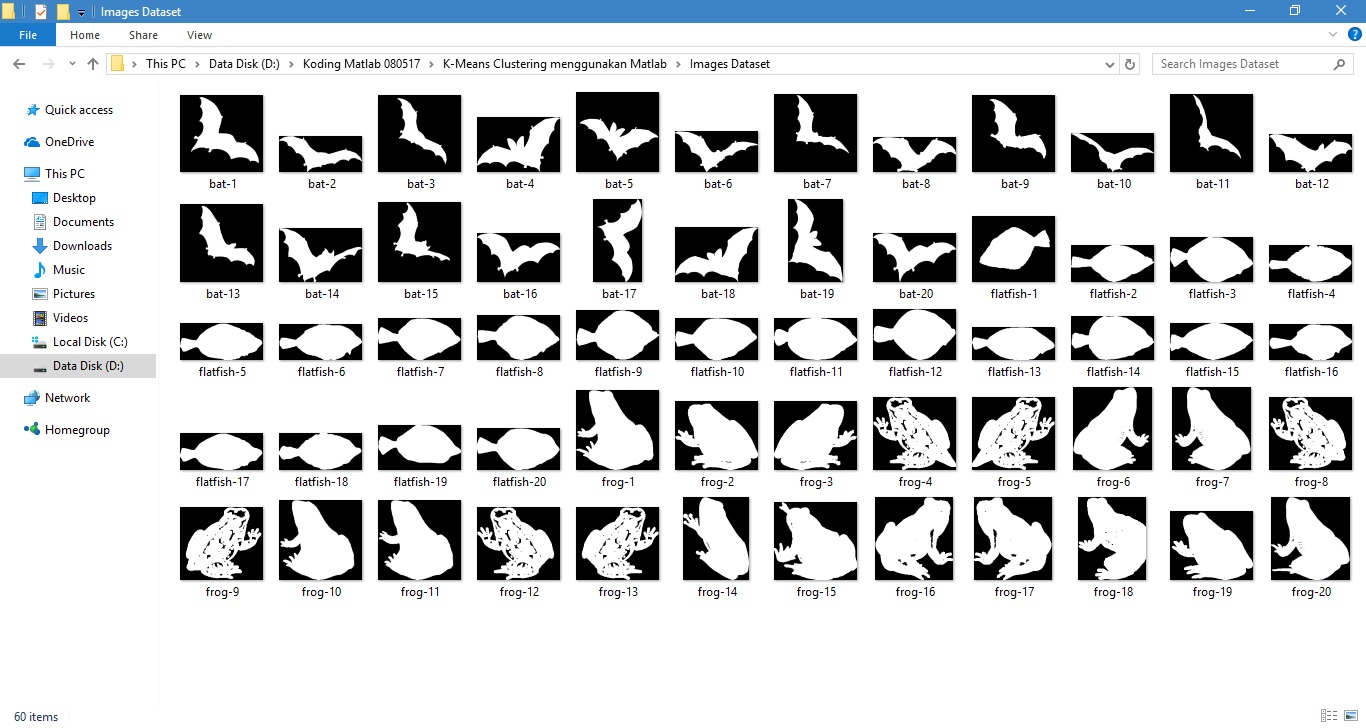
Secara visual, berdasarkan bentuk objeknya, citra tersebut terbagi menjadi tiga kelompok yaitu kelelawar, ikan, dan katak.
Oleh sebab itu, pada contoh ini jumlah kluster yang digunakan dalam algoritma k-means adalah sebanyak tiga buah.
Sedangkan ciri yang digunakan untuk membedakan ketiga jenis citra tersebut adalah luas dan keliling.
Source code untuk melakukan klustering menggunakan algoritma k-means adalah sebagai berikut:
clc; clear; close all;
image_folder = 'Images Dataset';
filenames = dir(fullfile(image_folder, '*.gif'));
total_images = numel(filenames);
area = zeros(1,total_images);
perimeter = zeros(1,total_images);
for n = 1:total_images
full_name = fullfile(image_folder, filenames(n).name);
our_images = logical(imread(full_name));
our_images = bwconvhull(our_images,'objects');
our_images = bwareaopen(our_images,100);
stats = regionprops(our_images,'All');
area(n) = stats.Area;
perimeter(n) = stats.Perimeter;
X = [area;perimeter]';
end
opts = statset('Display','final');
[idx,C] = kmeans(X,3,'Distance','sqeuclidean',...
'Replicates',5,'Options',opts);
figure;
plot(X(idx==1,1),X(idx==1,2),'r.','MarkerSize',24)
hold on
grid on
plot(X(idx==2,1),X(idx==2,2),'g.','MarkerSize',24)
plot(X(idx==3,1),X(idx==3,2),'b.','MarkerSize',24)
plot(C(:,1),C(:,2),'kx',...
'MarkerSize',15,'LineWidth',3)
legend('Cluster 1','Cluster 2','Cluster 3','Centroids',...
'Location','best')
title('Cluster Assignments and Centroids')
xlabel('Area')
ylabel('Perimeter')
hold off
Setelah koding tersebut dijalankan, maka akan menghasilkan grafik seperti pada gambar di bawah ini
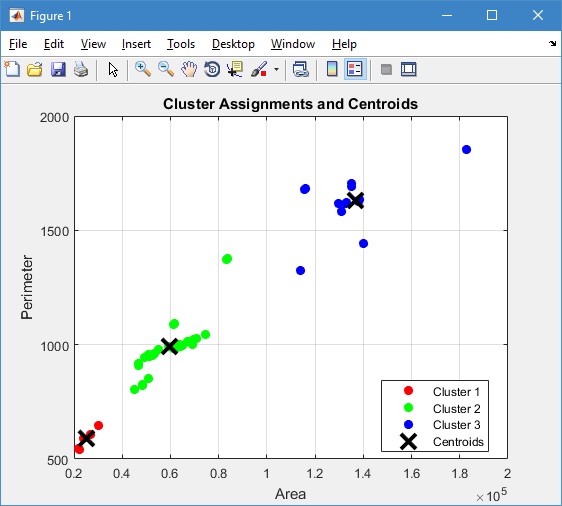
Pada grafik tersebut tampak bahwa algoritma k-means telah berhasil mengelompokkan data luas (area) dan keliling (perimeter) menjadi tiga kluster.
Hasil dari pengelompokkan data tersebut ditunjukkan pada tabel berikut:
| No | Class Index |
| 1 | 2 |
| 2 | 2 |
| 3 | 2 |
| 4 | 3 |
| 5 | 3 |
| 6 | 2 |
| 7 | 2 |
| 8 | 2 |
| 9 | 2 |
| 10 | 2 |
| 11 | 2 |
| 12 | 2 |
| 13 | 2 |
| 14 | 2 |
| 15 | 2 |
| 16 | 2 |
| 17 | 3 |
| 18 | 3 |
| 19 | 3 |
| 20 | 3 |
| 21 | 2 |
| 22 | 3 |
| 23 | 3 |
| 24 | 3 |
| 25 | 3 |
| 26 | 3 |
| 27 | 3 |
| 28 | 3 |
| 29 | 3 |
| 30 | 3 |
| 31 | 3 |
| 32 | 3 |
| 33 | 3 |
| 34 | 3 |
| 35 | 3 |
| 36 | 3 |
| 37 | 3 |
| 38 | 3 |
| 39 | 3 |
| 40 | 3 |
| 41 | 3 |
| 42 | 3 |
| 43 | 3 |
| 44 | 1 |
| 45 | 1 |
| 46 | 2 |
| 47 | 3 |
| 48 | 1 |
| 49 | 1 |
| 50 | 1 |
| 51 | 1 |
| 52 | 1 |
| 53 | 3 |
| 54 | 1 |
| 55 | 1 |
| 56 | 1 |
| 57 | 3 |
| 58 | 3 |
| 59 | 1 |
| 60 | 1 |
Tabel tersebut menunjukkan bahwa setiap data telah berhasil dikelompokkan meskipun memang terdapat beberapa data tidak sesuai dengan kelas klusternya.
Akurasi yang dihasilkan pada proses klustering tersebut yaitu 45/60*100 = 75%.
Hal ini menunjukkan bahwa algoritma k-means cukup baik dalam mengelompokkan tiga jenis citra masukan yang diberikan.
File source code lengkap beserta citra untuk pengenalan pola citra menggunakan algoritma k-means clustering dapat diperoleh melalui halaman berikut ini: Source Code
Sedangkan materi mengenai algoritma k-means clustering dan naive bayes classifier untuk pengenalan pola tesktur dapat dilihat pada: Algoritma k-means clustering dan naive bayes classifier untuk pengenalan pola tesktur









































mas mau nanya, cara mengaplikasikan algoritma k-means pada object gimana ya mas tahap2nya, jd dr inputan gambar kita olah pake algoritma k-means lalu hasil hitungnya untuk menentukan result kategorinya. mohon bantuannya 🙂
Materi mengenai pengolahan citra dan pengenalan pola menggunakan algoritma k-means clustering dapat dilihat melalui halaman berikut ini
mas mau nanya program nya sudah bisa dijalankan, grafik keluar sama seperti di atas
tetapi bagaimana cara menampilkan tabel class index nya ya?
untuk menampilkan tabel class index bisa dilakukan cara dengan membuka variabel idx yang ada pada workspace
ok mas bisa terima kasih
sama sama putro
Hitung presentasi akurasi ny pake apa mas?
bisa menggunakan persentase akurasi
maaf mas mau tanya datasetnya ngambil dari mana?
bisa kah melakukan deteksi bangunan dari citra satelit dengan k – mean cluster ?
bisa dicoba diimplementasikan untuk deteksi bangunan dari citra satelit
ok mas thanks
Kalo datanya pake angka kodingannya gmn kak. Kalo yg kmeans clustering yg disini kan rata2 pake gambar. Kalo yg pake data gmn yaa?
Pada prinsipnya sama saja karena ciri yang diekstrak dari citra adalah berupa angka
mas kalau untuk puluhan citra sarannya pake klasifikasi apa nih mas ?
naivbayes bisa ?
Ada banyak algoritma klasifikasi yang bisa dicoba diterapkan salah satunya kmeans clustering
mau tanya apakah bisa dilakukan proses morfologi setelah k-means
mau tanya ketika melakukan 2 clustering dengan 2 methode k-means dan fcm kemudian mengeluarkan hasil presentasi akurasi dari keduanya gmna ya ?
Ini kalau blm bisa jalan bagaimana ya? Apa yg kurang & harus dilengkapi?
Data dan source code lengkap bisa dibeli melalui tokopedia sehingga bisa langsung dijalankan dan dikembangkan
apa untuk klustering K-means bisa di jadikan untuk memprediksi?
Bisa saja, tidak masalah