Blog Archives
Metode Ekstraksi Fitur Dalam Pengolahan Citra
Pada era digital saat ini, pengolahan citra telah menjadi bidang yang semakin penting dalam berbagai aplikasi, termasuk pengenalan pola, deteksi objek, komputer vision, dan banyak lagi. Salah satu aspek penting dalam pengolahan citra adalah ekstraksi fitur, di mana informasi yang relevan diekstraksi dari citra untuk tujuan analisis lebih lanjut. Dalam artikel ini, kita akan mempelajari metode-metode ekstraksi fitur citra, mulai dari pendekatan sederhana hingga teknik-teknik kompleks yang digunakan dalam penelitian terkini.
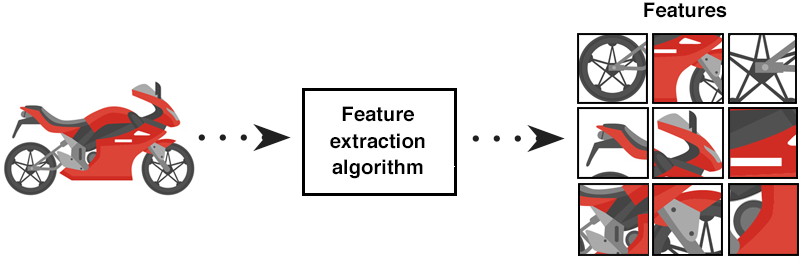
Ekstraksi fitur citra adalah proses mengubah data citra menjadi representasi fitur yang lebih sederhana dan informatif. Fitur-fitur ini mencerminkan karakteristik penting dari citra yang dapat digunakan untuk mengidentifikasi pola, membedakan objek, atau mengklasifikasikan citra. Dalam banyak aplikasi, ekstraksi fitur merupakan langkah awal yang penting sebelum analisis lebih lanjut, seperti pengenalan pola atau deteksi objek.
-read more->Source Code MATLAB: Klasifikasi Jenis Daun Menggunakan Algoritma Adaptive Neuro-Fuzzy Inference System (ANFIS)
Pengolahan citra telah berkembang pesat dalam berbagai bidang, termasuk dalam identifikasi dan klasifikasi jenis daun. Artikel ini membahas penerapan teknik pengolahan citra untuk mengklasifikasikan jenis daun dengan menggunakan algoritma Adaptive Neuro-Fuzzy Inference System (ANFIS). Proses pengolahan citra melibatkan segmentasi citra menggunakan metode Otsu Thresholding dan ekstraksi ciri bentuk dan tekstur. Kombinasi metode ini memberikan hasil yang akurat dalam mengidentifikasi jenis daun dengan akurasi yang tinggi.

Pengenalan jenis daun memiliki berbagai aplikasi penting dalam ilmu pertanian, ekologi, dan konservasi alam. Teknologi pengolahan citra telah menjadi alat yang sangat berguna dalam mengotomatisasi proses ini. Berikut ini merupakan langkah-langkah pengolahan citra yang digunakan untuk mengklasifikasikan jenis daun menggunakan algoritma ANFIS.
-read more->Klasifikasi Citra Daun Menggunakan Algoritma Jaringan Syaraf Tiruan Backpropagation
Jaringan Syaraf Tiruan Backpropagation adalah algoritma machine learning yang digunakan untuk klasifikasi dan regresi data. Berikut adalah beberapa konsep penting terkait dengan algoritma Jaringan Syaraf Tiruan Backpropagation:
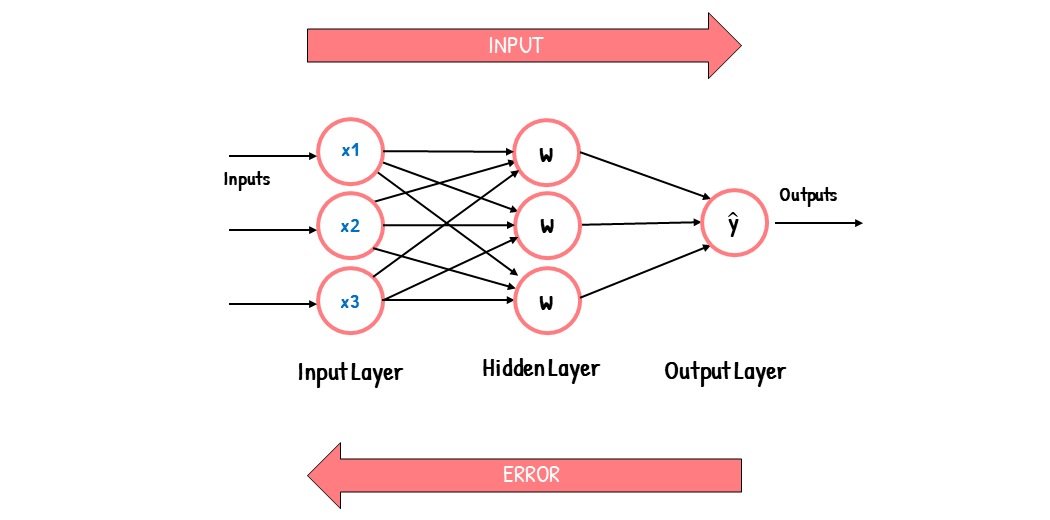
- Neuron buatan: Unit dasar jaringan syaraf tiruan adalah neuron buatan. Neuron buatan mewakili unit pemrosesan jaringan. Model neuron buatan yang diusulkan oleh McCulloch Pitts digunakan dalam aplikasi klasifikasi pola jaringan syaraf tiruan.
- Backpropagation: Backpropagation adalah metode pelatihan jaringan syaraf tiruan yang diawasi. Tujuan backpropagation adalah untuk memodifikasi bobot untuk melatih jaringan neural untuk memetakan input arbitrer ke output dengan benar. Perceptron berlapis-lapis dapat dilatih menggunakan algoritma backpropagasi.
- Arsitektur: Arsitektur jaringan syaraf tiruan backpropagation terdiri dari lapisan input, lapisan tersembunyi, dan lapisan output. Lapisan tersembunyi dapat memiliki beberapa lapisan tergantung pada kompleksitas masalah.
- Bobot: Bobot adalah parameter yang digunakan untuk menghubungkan neuron dalam jaringan syaraf tiruan. Bobot diatur selama pelatihan jaringan syaraf tiruan untuk meminimalkan kesalahan.
- Bias: Bias adalah parameter yang digunakan untuk menambahkan offset ke keluaran neuron. Bias juga diatur selama pelatihan jaringan syaraf tiruan untuk meminimalkan kesalahan.
Klasifikasi Citra Buah Apel Menggunakan Algoritma K-Nearest Neighbors (K-NN)
K-Nearest Neighbors (K-NN) adalah algoritma machine learning yang digunakan untuk klasifikasi dan regresi data. Berikut adalah beberapa konsep penting terkait K-NN:

- K-NN: K-NN mencari k titik data terdekat dari data yang akan diprediksi. K-NN kemudian memprediksi label atau nilai target dari data yang akan diprediksi berdasarkan mayoritas label atau nilai target dari k titik data terdekat.
- Jarak: K-NN menggunakan jarak Euclidean atau jarak Manhattan untuk mengukur jarak antara titik data.
- Kelas: K-NN digunakan untuk klasifikasi data. K-NN memprediksi label atau kelas dari data berdasarkan mayoritas label atau kelas dari k titik data terdekat.
- Regresi: K-NN juga dapat digunakan untuk regresi data. K-NN memprediksi nilai target dari data berdasarkan rata-rata nilai target dari k titik data terdekat.
Klasifikasi Citra Buah Menggunakan Algoritma Linear Discriminant Analysis (LDA)
Linear Discriminant Analysis (LDA) adalah algoritma pembelajaran mesin yang digunakan untuk klasifikasi dan reduksi dimensi data. Berikut adalah beberapa konsep penting terkait LDA:
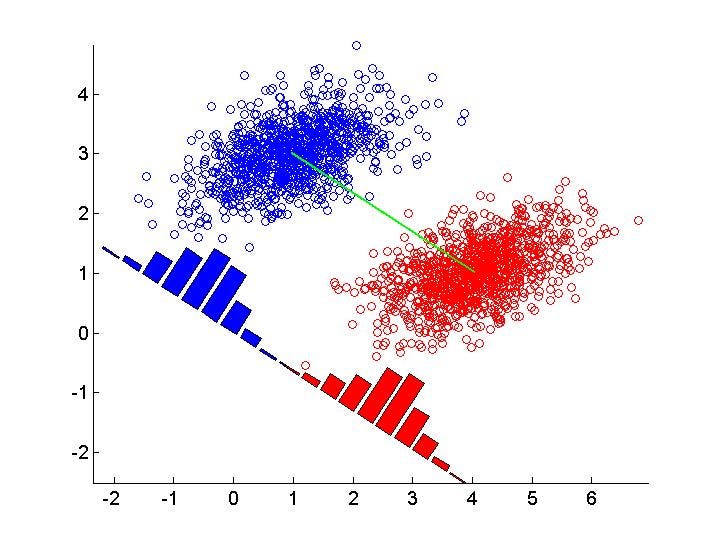
- Teorema Bayes: LDA didasarkan pada teorema Bayes, yang digunakan untuk menghitung probabilitas kondisional. Teorema Bayes menyatakan bahwa probabilitas suatu hipotesis atau kelas tertentu, diberikan data yang diamati, dapat dihitung dari probabilitas data yang diamati, diberikan hipotesis atau kelas tertentu.
- Reduksi dimensi: LDA digunakan untuk mengurangi dimensi data dengan memproyeksikan data ke dalam ruang dimensi yang lebih rendah. Proyeksi dilakukan dengan mencari kombinasi linear dari fitur yang memaksimalkan pemisahan antara kelas.
- Klasifikasi: LDA juga dapat digunakan untuk klasifikasi data. Setelah dimensi data direduksi, LDA membangun model klasifikasi dengan menghitung probabilitas kondisional untuk setiap kelas.
- Canonical Discriminant Analysis (CDA): CDA adalah variasi dari LDA yang mencari sumbu (koordinat kanonik) yang terbaik memisahkan kelas-kelas data. Sumbu-sumbu ini tidak berkorelasi satu sama lain dan mendefinisikan ruang optimal yang memisahkan kelas-kelas data.
Klasifikasi Sayuran Menggunakan Algoritma Naive Bayes
Naive Bayes classifier adalah algoritma pembelajaran mesin yang digunakan untuk klasifikasi data. Berikut adalah beberapa konsep penting yang terkait dengan Naive Bayes classifier:
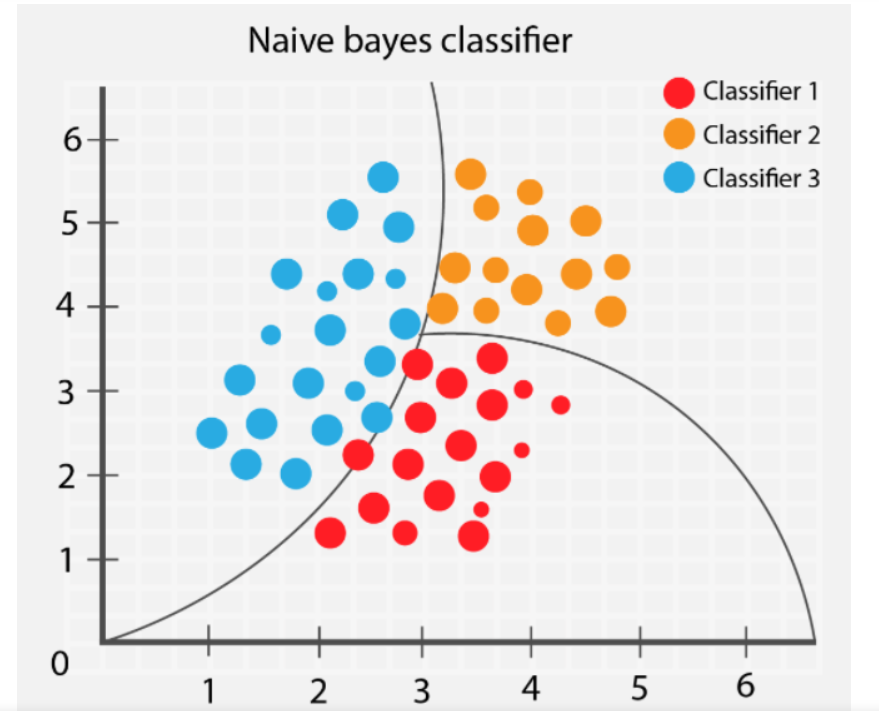
- Bayes’ Theorem: Naive Bayes classifier didasarkan pada teorema Bayes, yang digunakan untuk menghitung probabilitas kondisional. Teorema Bayes menyatakan bahwa probabilitas suatu hipotesis atau kelas tertentu, diberikan data yang diamati, dapat dihitung dari probabilitas data yang diamati, diberikan hipotesis atau kelas tertentu.
- Probabilitas kondisional: Probabilitas kondisional adalah probabilitas suatu kejadian terjadi, diberikan kejadian lain telah terjadi. Dalam Naive Bayes classifier, probabilitas kondisional digunakan untuk menghitung probabilitas suatu kelas, diberikan nilai fitur dari data.
- Fitur: Fitur adalah variabel yang digunakan untuk menggambarkan data. Dalam Naive Bayes classifier, fitur digunakan untuk memprediksi kelas dari data.
- Kelas: Kelas adalah label atau kategori yang diberikan pada data. Dalam Naive Bayes classifier, kelas digunakan untuk memprediksi label atau kategori dari data.
- Naive Bayes Assumption: Naive Bayes classifier mengasumsikan bahwa semua fitur dalam data adalah independen satu sama lain. Meskipun asumsi ini sering kali tidak benar dalam dunia nyata, Naive Bayes classifier tetap efektif dalam banyak kasus.
Klasifikasi Bunga Menggunakan Algoritma Support Vector Machine (SVM)
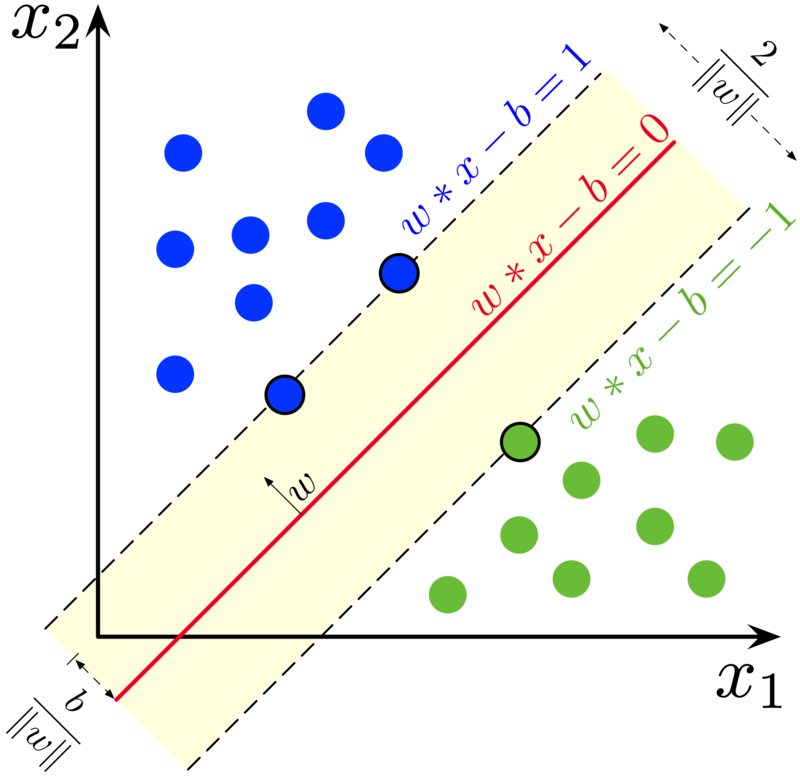
Support Vector Machine (SVM) adalah salah satu algoritma pembelajaran mesin yang digunakan untuk klasifikasi dan regresi data. SVM bekerja dengan membangun hyperplane atau serangkaian hyperplane di ruang dimensi tinggi atau tak terbatas, yang dapat digunakan untuk klasifikasi, regresi, atau tugas lain seperti deteksi outlier. SVM memilih titik-titik ekstrim atau vektor yang membantu dalam membuat hyperplane. Titik-titik ekstrim ini disebut sebagai support vector, dan oleh karena itu algoritma ini disebut sebagai Support Vector Machine. SVM dapat digunakan untuk berbagai tugas seperti klasifikasi teks, klasifikasi gambar, deteksi spam, identifikasi tulisan tangan, analisis ekspresi gen, deteksi wajah, dan deteksi anomali.
Deteksi Kematangan Buah Sawit Menggunakan Algoritma Self-Organizing Map (SOM)
Pengolahan citra digital telah mengalami perkembangan yang pesat dalam beberapa dekade terakhir, memungkinkan aplikasi yang luas dalam berbagai bidang seperti kedokteran, pertanian, industri, dan lain-lain. Salah satu langkah penting dalam pengolahan citra adalah klasifikasi, yaitu memisahkan objek atau pola yang berbeda dalam citra menjadi kategori atau kelas yang sesuai. Dalam hal ini, Algoritma Self-Organizing Map (SOM) telah muncul sebagai salah satu pendekatan yang kuat dan efektif dalam melakukan klasifikasi citra digital.
Identifikasi Tingkat Kematangan Buah Jeruk Menggunakan Metode K-Nearest Neighbor (K-NN)
Buah jeruk adalah salah satu komoditas buah yang sangat populer dan memiliki nilai gizi yang tinggi. Identifikasi tingkat kematangan buah jeruk dengan akurasi yang tinggi menjadi kunci dalam memastikan kualitas produk dan pengelolaan persediaan yang efisien. Dalam upaya ini, pengolahan citra dengan metode K-Nearest Neighbor (K-NN) telah terbukti menjadi alat yang efektif dalam mengatasi tantangan tersebut dengan ketepatan dan reliabilitas.

Pengolahan citra telah membuka peluang besar dalam berbagai aspek kehidupan, termasuk dalam dunia pertanian dan agroteknologi. Dalam konteks identifikasi tingkat kematangan buah jeruk, penggunaan teknologi pengolahan citra memungkinkan analisis objektif dan mendalam terhadap atribut-atribut visual yang berkaitan dengan kematangan buah.
-read more->")
Identifikasi Tingkat Kematangan Buah Pepaya Menggunakan Metode Support Vector Machine (SVM)
Buah pepaya adalah salah satu buah tropis yang memiliki nilai gizi tinggi dan manfaat kesehatan yang penting. Pengidentifikasian tingkat kematangan buah pepaya dengan akurasi tinggi merupakan langkah penting dalam industri pertanian dan distribusi. Dalam konteks ini, pengolahan citra dengan metode Support Vector Machine (SVM) telah terbukti efektif dalam mengatasi tantangan ini dengan presisi dan kehandalan.

Pengolahan citra telah mengalami kemajuan pesat dalam berbagai bidang, termasuk pertanian. Teknologi ini memungkinkan analisis objektif dan otomatis terhadap citra, termasuk identifikasi tingkat kematangan buah pepaya. Buah pepaya mengalami perubahan warna dan tekstur yang signifikan selama pematangan, dan penggunaan SVM membantu mengenali pola-pola yang rumit dalam citra.
-read more->