Category Archives: Pengenalan Pola
Pengenalan Pola menggunakan MATLAB
Klasifikasi Jenis Burung Love Bird dengan Metode K-Means Clustering berdasarkan Ciri Warna YCbCr
K-means clustering adalah algoritma unsupervised learning yang digunakan untuk mengelompokkan atau menggabungkan dataset yang tidak berlabel ke dalam kelompok yang berbeda. Tujuannya adalah untuk mempartisi sekelompok pengamatan menjadi k kelompok, di mana setiap pengamatan termasuk ke dalam kelompok dengan rata-rata terdekat (titik tengah kelompok). Algoritma k-means bekerja dengan cara secara iteratif menetapkan titik data ke pusat klaster terdekat dan memperbarui pusat klaster berdasarkan rata-rata data yang ditetapkan. K-means clustering dapat digunakan dalam berbagai aplikasi contohnya untuk klasifikasi jenis burung Love Bird.

Identifikasi Kesegaran Ikan Nila Menggunakan Metode K-Nearest neighbor (K-NN)
Gray Level Co-occurrence Matrix (GLCM) adalah metode ekstraksi ciri tekstur pada citra digital yang menghitung frekuensi kemunculan pasangan nilai intensitas piksel dalam citra pada jarak dan arah tertentu. GLCM merepresentasikan hubungan spasial antara dua piksel dalam citra dan dapat digunakan untuk mengukur ciri tekstur seperti kekasaran, kehalusan, dan kehomogenan pada citra. GLCM dapat digunakan bersama-sama dengan metode ekstraksi ciri lainnya, seperti momen warna HSV, untuk meningkatkan akurasi pengenalan citra. GLCM telah banyak digunakan dalam berbagai aplikasi contohnya seperti identifikasi kesegaran ikan nila.

Template Matching Menggunakan MATLAB
Template matching adalah sebuah teknik dalam pengolahan citra digital untuk mencari bagian kecil dari sebuah citra yang cocok dengan sebuah citra template. Berikut adalah beberapa informasi mengenai template matching:
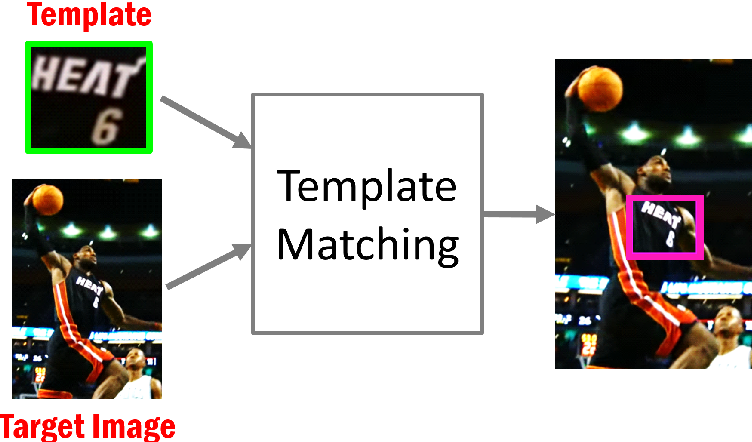
- Template matching digunakan untuk berbagai aplikasi, seperti pengenalan objek, deteksi wajah, dan pengenalan karakter.
- Template matching bekerja dengan cara memindai citra dengan citra template dan mencari bagian citra yang cocok dengan citra template. Citra template adalah sebuah citra kecil yang digunakan sebagai acuan untuk mencari bagian citra yang cocok.
- Template matching dapat dilakukan dengan menggunakan berbagai metode, seperti metode cross-correlation dan metode normalized cross-correlation. Metode cross-correlation menghitung korelasi antara citra template dan citra yang dipindai, sedangkan metode normalized cross-correlation menghitung korelasi yang dinormalisasi antara citra template dan citra yang dipindai.
- Template matching dapat dihitung menggunakan berbagai bahasa pemrograman dan pustaka pengolahan citra digital, seperti MATLAB dan OpenCV.
- Template matching memiliki beberapa kelemahan, seperti sensitivitas terhadap perubahan skala, rotasi, dan pergeseran citra. Oleh karena itu, template matching sering digunakan dalam kombinasi dengan teknik pengolahan citra lainnya untuk meningkatkan akurasi dan keandalan sistem.
Klasifikasi Kualitas Biji Kopi Menggunakan Metode Gray Level Co-occurrence Matrix (GLCM) Dan K-Nearest Neighbor (K-NN)
Gray Level Co-occurrence Matrix (GLCM) adalah sebuah matriks yang digunakan untuk menganalisis tekstur pada citra digital. Berikut adalah beberapa informasi mengenai GLCM:
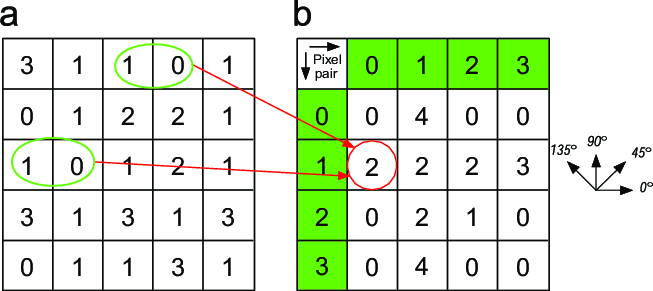
- GLCM digunakan untuk mengukur hubungan antara nilai piksel pada citra digital. Matriks ini menghitung frekuensi kemunculan pasangan nilai piksel yang berada pada jarak dan arah tertentu pada citra.
- GLCM dapat digunakan untuk menghasilkan berbagai fitur tekstur pada citra, seperti kontras, homogenitas, dan energi. Fitur-fitur ini dapat digunakan untuk mengklasifikasikan citra atau membedakan citra dari kelas yang berbeda.
- GLCM dapat dihitung dengan cara menghitung frekuensi kemunculan pasangan nilai piksel pada citra dengan jarak dan arah tertentu. Hasilnya adalah sebuah matriks yang berisi frekuensi kemunculan pasangan nilai piksel pada citra.
- GLCM dapat dihitung pada citra grayscale maupun citra berwarna. Pada citra berwarna, GLCM dapat dihitung pada setiap saluran warna (misalnya merah, hijau, dan biru) atau pada citra grayscale yang dihasilkan dari konversi citra berwarna ke grayscale.
- GLCM dapat dihitung menggunakan berbagai bahasa pemrograman, seperti Python dan MATLAB. Terdapat pustaka-pustaka khusus yang dapat digunakan untuk menghitung GLCM pada citra digital.
- GLCM dapat digunakan dalam berbagai aplikasi, seperti pengenalan pola, pengolahan citra medis, dan pengenalan objek pada citra.
Deteksi Dan Ekstraksi Ciri Wajah Menggunakan Algoritma Viola-Jones
Deteksi wajah dengan metode Viola-Jones adalah sebuah algoritma yang digunakan untuk mendeteksi wajah pada gambar atau video. Berikut adalah beberapa informasi mengenai deteksi wajah dengan metode Viola-Jones:

- Metode Viola-Jones menggunakan fitur Haar sebagai deskriptor untuk mendeteksi wajah. Fitur Haar adalah pola piksel yang digunakan untuk mengidentifikasi bagian wajah seperti mata, hidung, dan mulut.
- Algoritma Viola-Jones terdiri dari tiga komponen penting, yaitu integral image, Adaboost, dan cascade classifier. Integral image digunakan untuk menghitung jumlah piksel dalam suatu area tertentu dengan cepat. Adaboost digunakan untuk memilih fitur-fitur Haar yang paling relevan dalam mendeteksi wajah. Cascade classifier adalah serangkaian classifier yang digunakan untuk memfilter area yang tidak relevan sehingga meningkatkan kecepatan deteksi.
- Metode Viola-Jones memiliki tingkat akurasi yang tinggi dan komputasi yang cepat. Hal ini membuatnya menjadi salah satu metode yang populer dalam deteksi wajah.
- Metode Viola-Jones dapat dimodifikasi dengan memodifikasi nilai-nilai parameter yang ada untuk meningkatkan tingkat akurasi sistem.
- Implementasi metode Viola-Jones dapat dilakukan menggunakan berbagai platform, termasuk Android dan FPGA (Field Programmable Gate Arrays).
Pengenalan Wajah Menggunakan Algoritma Principal Component Analysis (PCA)
Principal Component Analysis (PCA) adalah teknik analisis statistik yang digunakan untuk mengurangi dimensi data. Berikut adalah beberapa konsep penting terkait PCA:

- Dimensi data: Dimensi data adalah jumlah variabel atau fitur dalam dataset. PCA digunakan untuk mengurangi dimensi data dengan memproyeksikan data ke dalam ruang dimensi yang lebih rendah.
- Komponen utama: Komponen utama adalah kombinasi linear dari variabel dalam dataset yang menjelaskan sebagian besar variasi dalam data. PCA mencari komponen utama dengan memaksimalkan varians data yang dijelaskan oleh setiap komponen.
- Varians: Varians adalah ukuran seberapa tersebar data dalam satu dimensi. PCA memilih komponen utama yang memiliki varians tertinggi untuk mempertahankan sebanyak mungkin informasi dalam data.
- Reduksi dimensi: PCA digunakan untuk reduksi dimensi data dengan memproyeksikan data ke dalam ruang dimensi yang lebih rendah. Proyeksi dilakukan dengan mencari kombinasi linear dari fitur yang memaksimalkan pemisahan antara kelas.
Klasifikasi Citra Daun Menggunakan Algoritma Jaringan Syaraf Tiruan Backpropagation
Jaringan Syaraf Tiruan Backpropagation adalah algoritma machine learning yang digunakan untuk klasifikasi dan regresi data. Berikut adalah beberapa konsep penting terkait dengan algoritma Jaringan Syaraf Tiruan Backpropagation:
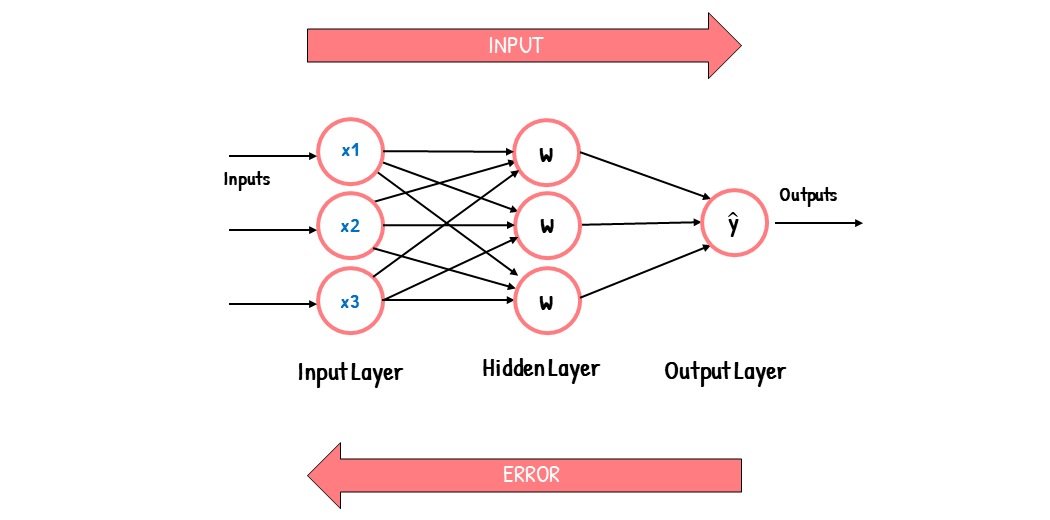
- Neuron buatan: Unit dasar jaringan syaraf tiruan adalah neuron buatan. Neuron buatan mewakili unit pemrosesan jaringan. Model neuron buatan yang diusulkan oleh McCulloch Pitts digunakan dalam aplikasi klasifikasi pola jaringan syaraf tiruan.
- Backpropagation: Backpropagation adalah metode pelatihan jaringan syaraf tiruan yang diawasi. Tujuan backpropagation adalah untuk memodifikasi bobot untuk melatih jaringan neural untuk memetakan input arbitrer ke output dengan benar. Perceptron berlapis-lapis dapat dilatih menggunakan algoritma backpropagasi.
- Arsitektur: Arsitektur jaringan syaraf tiruan backpropagation terdiri dari lapisan input, lapisan tersembunyi, dan lapisan output. Lapisan tersembunyi dapat memiliki beberapa lapisan tergantung pada kompleksitas masalah.
- Bobot: Bobot adalah parameter yang digunakan untuk menghubungkan neuron dalam jaringan syaraf tiruan. Bobot diatur selama pelatihan jaringan syaraf tiruan untuk meminimalkan kesalahan.
- Bias: Bias adalah parameter yang digunakan untuk menambahkan offset ke keluaran neuron. Bias juga diatur selama pelatihan jaringan syaraf tiruan untuk meminimalkan kesalahan.
Klasifikasi Citra Buah Apel Menggunakan Algoritma K-Nearest Neighbors (K-NN)
K-Nearest Neighbors (K-NN) adalah algoritma machine learning yang digunakan untuk klasifikasi dan regresi data. Berikut adalah beberapa konsep penting terkait K-NN:

- K-NN: K-NN mencari k titik data terdekat dari data yang akan diprediksi. K-NN kemudian memprediksi label atau nilai target dari data yang akan diprediksi berdasarkan mayoritas label atau nilai target dari k titik data terdekat.
- Jarak: K-NN menggunakan jarak Euclidean atau jarak Manhattan untuk mengukur jarak antara titik data.
- Kelas: K-NN digunakan untuk klasifikasi data. K-NN memprediksi label atau kelas dari data berdasarkan mayoritas label atau kelas dari k titik data terdekat.
- Regresi: K-NN juga dapat digunakan untuk regresi data. K-NN memprediksi nilai target dari data berdasarkan rata-rata nilai target dari k titik data terdekat.
Klasifikasi Citra Buah Menggunakan Algoritma Linear Discriminant Analysis (LDA)
Linear Discriminant Analysis (LDA) adalah algoritma pembelajaran mesin yang digunakan untuk klasifikasi dan reduksi dimensi data. Berikut adalah beberapa konsep penting terkait LDA:
- Teorema Bayes: LDA didasarkan pada teorema Bayes, yang digunakan untuk menghitung probabilitas kondisional. Teorema Bayes menyatakan bahwa probabilitas suatu hipotesis atau kelas tertentu, diberikan data yang diamati, dapat dihitung dari probabilitas data yang diamati, diberikan hipotesis atau kelas tertentu.
- Reduksi dimensi: LDA digunakan untuk mengurangi dimensi data dengan memproyeksikan data ke dalam ruang dimensi yang lebih rendah. Proyeksi dilakukan dengan mencari kombinasi linear dari fitur yang memaksimalkan pemisahan antara kelas.
- Klasifikasi: LDA juga dapat digunakan untuk klasifikasi data. Setelah dimensi data direduksi, LDA membangun model klasifikasi dengan menghitung probabilitas kondisional untuk setiap kelas.
- Canonical Discriminant Analysis (CDA): CDA adalah variasi dari LDA yang mencari sumbu (koordinat kanonik) yang terbaik memisahkan kelas-kelas data. Sumbu-sumbu ini tidak berkorelasi satu sama lain dan mendefinisikan ruang optimal yang memisahkan kelas-kelas data.
Klasifikasi Sayuran Menggunakan Algoritma Naive Bayes
Naive Bayes classifier adalah algoritma pembelajaran mesin yang digunakan untuk klasifikasi data. Berikut adalah beberapa konsep penting yang terkait dengan Naive Bayes classifier:
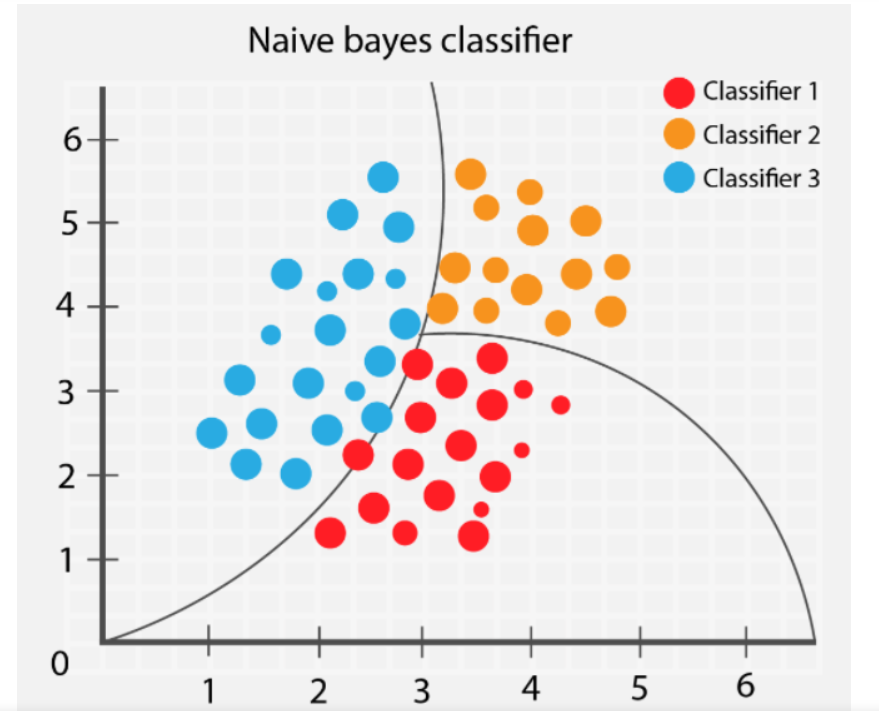
- Bayes’ Theorem: Naive Bayes classifier didasarkan pada teorema Bayes, yang digunakan untuk menghitung probabilitas kondisional. Teorema Bayes menyatakan bahwa probabilitas suatu hipotesis atau kelas tertentu, diberikan data yang diamati, dapat dihitung dari probabilitas data yang diamati, diberikan hipotesis atau kelas tertentu.
- Probabilitas kondisional: Probabilitas kondisional adalah probabilitas suatu kejadian terjadi, diberikan kejadian lain telah terjadi. Dalam Naive Bayes classifier, probabilitas kondisional digunakan untuk menghitung probabilitas suatu kelas, diberikan nilai fitur dari data.
- Fitur: Fitur adalah variabel yang digunakan untuk menggambarkan data. Dalam Naive Bayes classifier, fitur digunakan untuk memprediksi kelas dari data.
- Kelas: Kelas adalah label atau kategori yang diberikan pada data. Dalam Naive Bayes classifier, kelas digunakan untuk memprediksi label atau kategori dari data.
- Naive Bayes Assumption: Naive Bayes classifier mengasumsikan bahwa semua fitur dalam data adalah independen satu sama lain. Meskipun asumsi ini sering kali tidak benar dalam dunia nyata, Naive Bayes classifier tetap efektif dalam banyak kasus.