
Memahami Algoritma Naive Bayes: Konsep dan Penerapan
Algoritma Naive Bayes adalah pendekatan klasifikasi yang populer dalam dunia kecerdasan buatan dan pemrosesan bahasa alami. Artikel ini akan menjelaskan konsep dasar algoritma Naive Bayes, mengapa algoritma ini penting, serta bagaimana mengimplementasikannya dalam berbagai aplikasi.
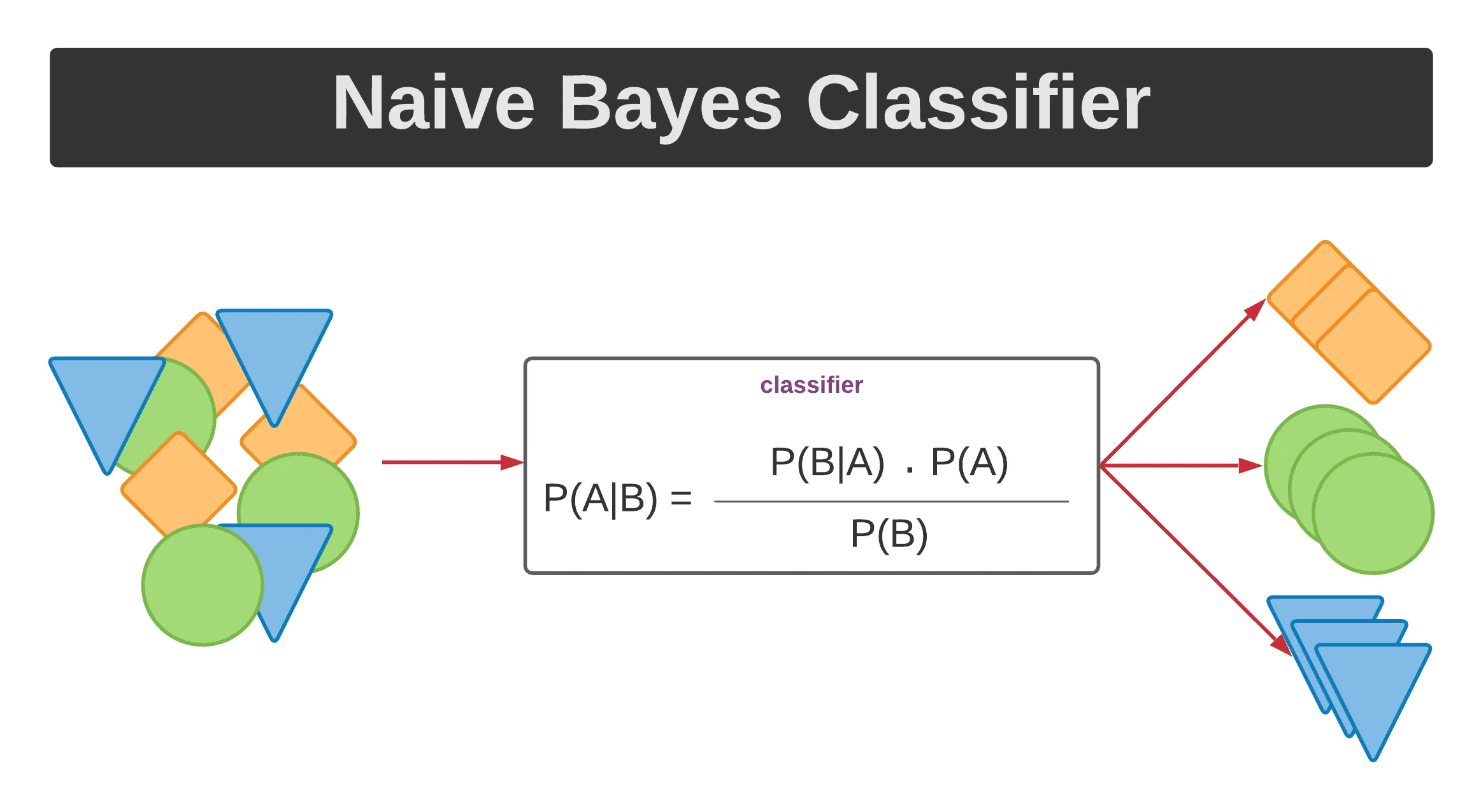
Algoritma Naive Bayes didasarkan pada teorema probabilitas Bayes dan digunakan untuk mengklasifikasikan data ke dalam kategori yang sesuai. Meskipun memiliki asumsi “naif” (sederhana) tentang independensi fitur, algoritma ini sering memberikan hasil yang memuaskan dalam berbagai konteks. Naive Bayes telah sukses diterapkan dalam spam filtering, analisis sentimen, klasifikasi dokumen, dan banyak aplikasi lainnya.
Konsep Dasar
Algoritma Naive Bayes mengandalkan perhitungan probabilitas untuk mengklasifikasikan data. Konsep dasar meliputi:
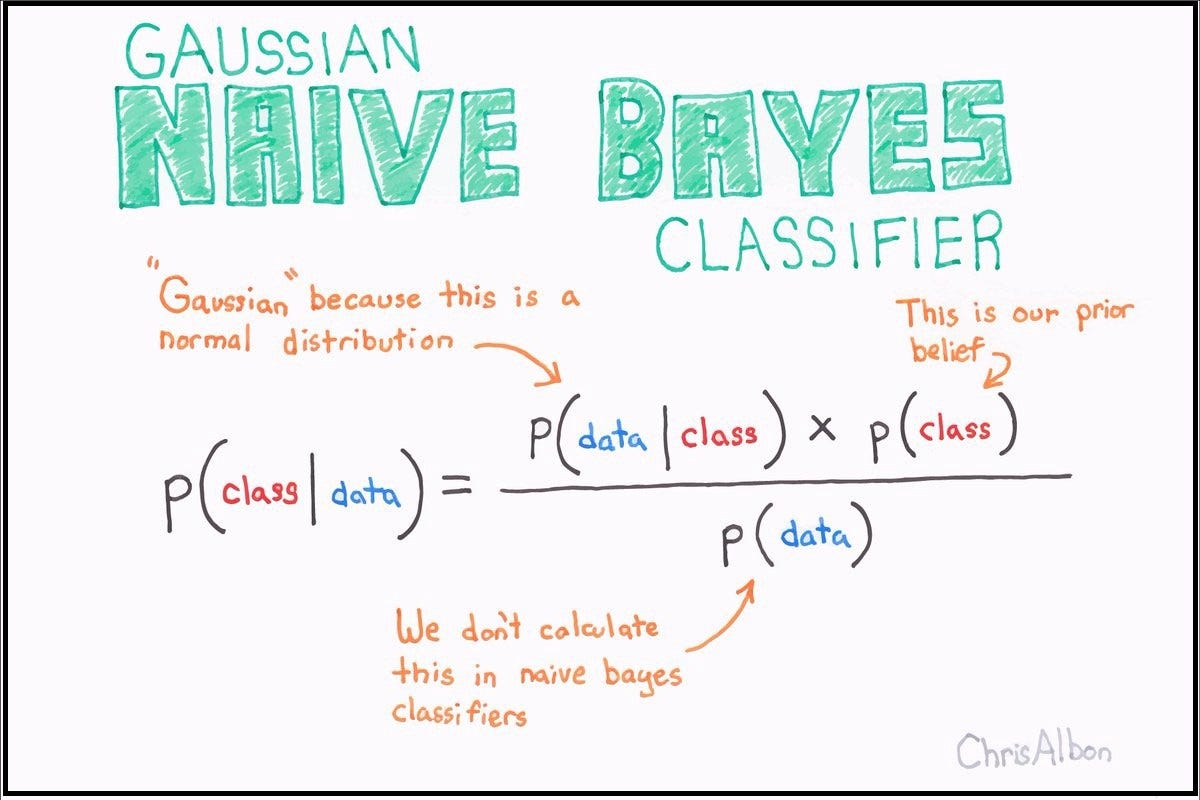
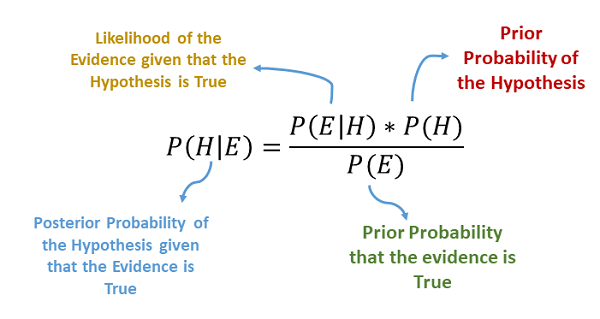
- Teorema Probabilitas Bayes: Algoritma ini menggunakan teorema probabilitas Bayes untuk menghitung probabilitas kelas yang mungkin berdasarkan fitur-fitur yang diamati.
- Asumsi Naive: Naive Bayes mengasumsikan bahwa setiap fitur independen dari yang lain, meskipun ini jarang terjadi dalam dunia nyata. Meskipun asumsi ini sederhana, algoritma ini sering memberikan hasil yang baik.
- Klasifikasi: Algoritma Naive Bayes mengklasifikasikan data ke dalam kategori yang memiliki probabilitas tertinggi berdasarkan fitur-fiturnya.
Manfaat dan Penerapan
Keuntungan dari algoritma Naive Bayes meliputi:
- Sederhana dan Cepat: Algoritma ini relatif sederhana dan memiliki kinerja yang baik dalam kasus tertentu.
- Pengenalan Pola: Naive Bayes cocok untuk masalah klasifikasi dan pengenalan pola, seperti klasifikasi teks dalam analisis sentimen.
Penerapan algoritma Naive Bayes meliputi:
- Spam Filtering: Dalam deteksi spam email, algoritma ini mengklasifikasikan email sebagai “spam” atau “bukan spam” berdasarkan isi teks.
- Klasifikasi Dokumen: Dalam pengelompokan dokumen berdasarkan topik atau genre, Naive Bayes dapat mengidentifikasi kategori yang paling sesuai.
- Analisis Sentimen: Algoritma ini dapat menentukan sentimen positif, negatif, atau netral dalam teks.
Implementasi Algoritma Naive Bayes
Berikut adalah langkah-langkah umum dalam mengimplementasikan algoritma Naive Bayes:
- Persiapan Data: Siapkan data yang akan digunakan untuk pelatihan dan pengujian.
- Perhitungan Probabilitas: Hitung probabilitas masing-masing fitur untuk setiap kategori.
- Prediksi: Gunakan probabilitas yang dihitung untuk memprediksi kategori yang paling mungkin untuk data baru.
- Evaluasi: Evaluasi kinerja algoritma menggunakan metrik seperti akurasi, presisi, dan recall.
Contoh Implementasi dalam MATLAB
% Persiapan Data
load fisheriris
X = meas;
Y = species;
% Membagi Data menjadi Data Latih dan Uji
cv = cvpartition(Y,'HoldOut',0.3);
XTrain = X(training(cv),:);
YTrain = Y(training(cv),:);
XTest = X(test(cv),:);
YTest = Y(test(cv),:);
% Melatih Model Naive Bayes
nbModel = fitcnb(XTrain, YTrain);
% Prediksi dan Evaluasi
YTestPred = predict(nbModel, XTest);
accuracy = sum(YTestPred == YTest) / numel(YTest);
confusionMatrix = confusionmat(YTest, YTestPred);
Algoritma Naive Bayes adalah metode klasifikasi yang berbasis pada teorema probabilitas Bayes. Meskipun memiliki asumsi sederhana tentang independensi fitur, algoritma ini telah berhasil diterapkan dalam berbagai konteks, dari analisis sentimen hingga spam filtering. Dengan pemahaman tentang konsep dasar dan langkah-langkah implementasinya, kita dapat memanfaatkan algoritma Naive Bayes untuk mengklasifikasikan dan mengenali pola dalam data.
Contoh penerapan algoritma Naive Bayes dalam klasifikasi citra menggunakan MATLAB ditunjukkan pada video berikut ini:
Posted on August 9, 2023, in Data mining, Pengenalan Pola, Pengolahan Citra and tagged Algoritma Klasifikasi, Algoritma Machine Learning, Data mining, Data Science, Evaluasi Model, Implementasi MATLAB, Independensi Fitur, kecerdasan buatan, Klasifikasi, Lingkungan Pemrograman, Model Klasifikasi, Naive Bayes, Pemrosesan Data, Pengenalan Pola, Prediksi, Probabilitas Kategori, Teorema Probabilitas, Teorema Probabilitas Bayes. Bookmark the permalink. Leave a comment.








































Leave a comment
Comments 0