
Prediksi Status Kelulusan Mahasiswa dengan Menggunakan Algoritma K-Nearest Neighbor (K-NN)
Pendidikan tinggi adalah salah satu tahapan penting dalam perjalanan menuju karir yang sukses. Namun, banyak faktor yang dapat mempengaruhi apakah seorang mahasiswa akan lulus tepat waktu, terlambat, atau bahkan drop out. Dalam upaya untuk membantu mahasiswa dan perguruan tinggi dalam memahami faktor-faktor tersebut, penelitian prediksi status kelulusan mahasiswa menjadi semakin penting. Dalam artikel ini, akan dijelaskan bagaimana algoritma K-Nearest Neighbor (K-NN) dapat digunakan untuk memprediksi status kelulusan mahasiswa berdasarkan beberapa variabel kunci, yaitu Indeks Prestasi Sementara (IPS), Status Pernikahan, Status Pekerjaan, dan Jumlah SKS (Satuan Kredit Semester).

Algoritma K-Nearest Neighbor (K-NN)
Algoritma K-Nearest Neighbor (K-NN) adalah salah satu algoritma machine learning yang digunakan untuk klasifikasi dan regresi. K-NN bekerja dengan cara mencari k-neighbors terdekat (tetangga terdekat) dari data yang akan diprediksi berdasarkan ukuran kesamaan, seperti jarak euclidean, dan kemudian mengambil mayoritas kelas tetangga tersebut untuk memprediksi kelas data yang akan diuji. Dalam kasus ini, akan diggunakan algoritma K-NN untuk klasifikasi status kelulusan mahasiswa.

Data yang Digunakan
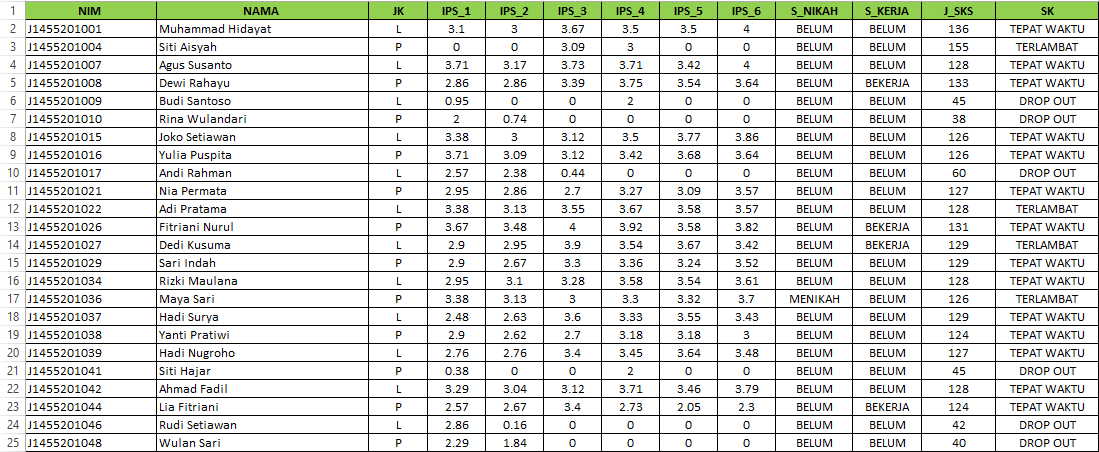
Data yang digunakan dalam analisis ini mencakup empat variabel utama:
- Indeks Prestasi Sementara (IPS): Nilai rata-rata sementara mahasiswa selama studi mereka.
- Status Pernikahan: Variabel ini memiliki dua nilai, yaitu “Sudah Menikah” dan “Belum Menikah”.
- Status Pekerjaan: Variabel ini juga memiliki dua nilai, yaitu “Sudah Bekerja” dan “Belum Bekerja”.
- Jumlah SKS (Satuan Kredit Semester): Jumlah SKS yang telah ditempuh oleh mahasiswa hingga saat ini.
Selain itu, kita memiliki variabel target yang akan kita prediksi, yaitu Status Kelulusan, yang dapat memiliki tiga nilai, yaitu “Tepat Waktu,” “Terlambat,” atau “Drop Out.”
Langkah-langkah Implementasi K-NN
- Pengumpulan Data: Pertama-tama, data mengenai IPS, status pernikahan, status pekerjaan, jumlah SKS, dan status kelulusan mahasiswa perlu dikumpulkan dan disiapkan untuk analisis.
- Preprocessing Data: Data seringkali memerlukan preprocessing sebelum digunakan dalam algoritma K-NN. Ini termasuk mengisi nilai yang hilang, normalisasi, atau pengkodean variabel kategori seperti status pernikahan dan status pekerjaan.
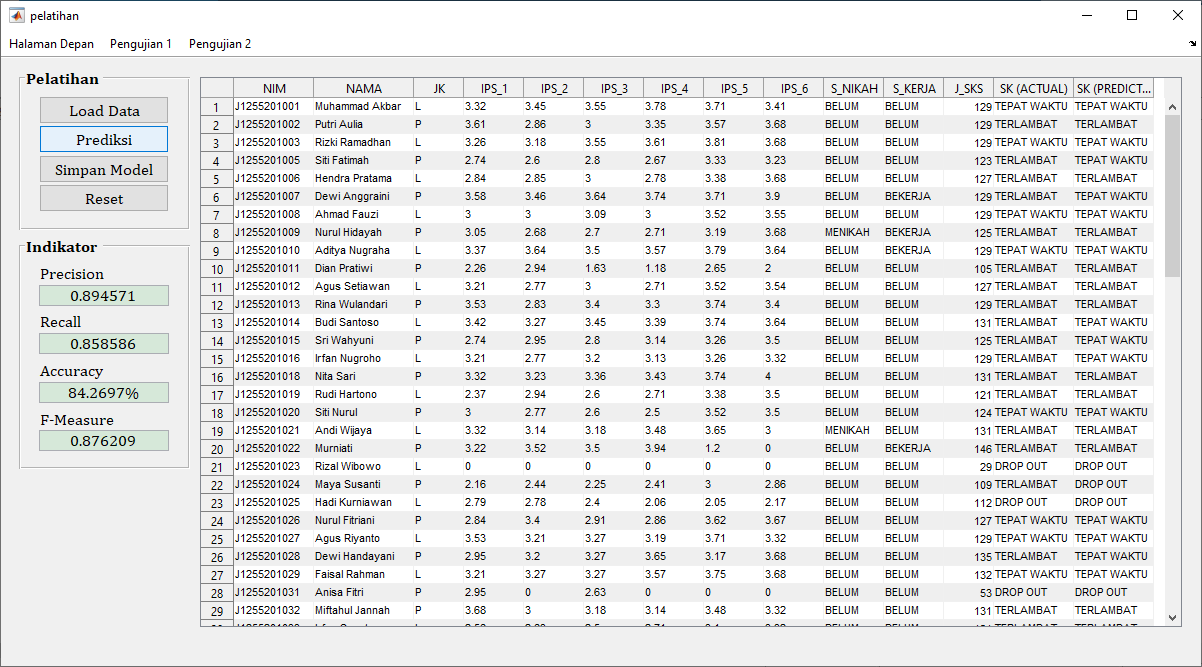
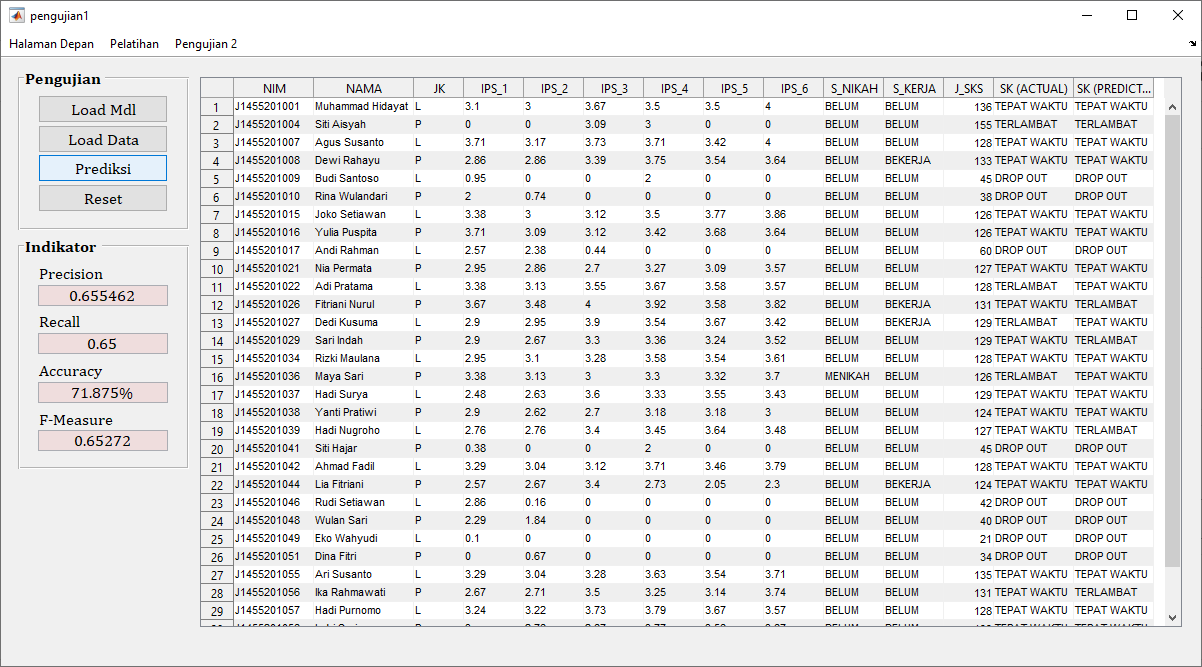
- Pembagian Data: Data perlu dibagi menjadi dua bagian: data pelatihan (training data) dan data pengujian (testing data). Data pelatihan digunakan untuk melatih model K-NN, sementara data pengujian digunakan untuk menguji kinerja model.
- Pemilihan Nilai K: Anda perlu memilih jumlah tetangga terdekat (K) yang akan digunakan dalam algoritma. Ini dapat dilakukan dengan mencoba beberapa nilai K dan memilih yang memberikan hasil terbaik.
- Pelatihan Model: Model K-NN dilatih dengan menggunakan data pelatihan, dan klasifikasi status kelulusan dilakukan berdasarkan nilai-nilai IPS, status pernikahan, status pekerjaan, dan jumlah SKS.
- Evaluasi Model: Model yang telah dilatih dievaluasi dengan menggunakan data pengujian untuk mengukur sejauh mana model tersebut dapat memprediksi status kelulusan dengan akurasi.
- Prediksi: Setelah model dianggap memadai, Anda dapat menggunakannya untuk memprediksi status kelulusan mahasiswa yang baru berdasarkan data yang tersedia.
Berikut ini adalah pseudocode untuk kasus prediksi status kelulusan mahasiswa menggunakan algoritma K-Nearest Neighbor (K-NN):
# Inisialisasi variabel
DataTraining = [] # Data latih
DataTesting = [] # Data uji
K = 5 # Jumlah tetangga terdekat yang akan dipertimbangkan
# Fungsi untuk menghitung jarak euclidean antara dua data
function HitungJarak(data1, data2):
jarak = 0
for i from 1 to jumlah_fitur:
jarak += (data1[i] - data2[i])^2
return akar_kuadrat(jarak)
# Fungsi untuk melakukan prediksi status kelulusan
function PrediksiStatusKelulusan(data_uji):
jarak_terdekat = []
for setiap data_latih in DataTraining:
jarak = HitungJarak(data_uji, data_latih)
tambahkan (jarak, data_latih[StatusKelulusan]) ke jarak_terdekat
Urutkan jarak_terdekat berdasarkan jarak secara ascending
Ambil K tetangga terdekat dari jarak_terdekat
# Menghitung mayoritas kelas tetangga
JumlahLulus = 0
JumlahTerlambat = 0
JumlahDropOut = 0
for setiap tetangga in K tetangga terdekat:
jika tetangga[StatusKelulusan] == "Lulus":
JumlahLulus++
elif tetangga[StatusKelulusan] == "Terlambat":
JumlahTerlambat++
else:
JumlahDropOut++
# Memilih kelas mayoritas sebagai hasil prediksi
jika JumlahLulus > JumlahTerlambat dan JumlahLulus > JumlahDropOut:
return "Lulus"
elif JumlahTerlambat > JumlahLulus dan JumlahTerlambat > JumlahDropOut:
return "Terlambat"
else:
return "Drop Out"
# Main program
Baca DataTraining dari file atau sumber data
Baca DataTesting dari file atau sumber data
untuk setiap data_uji in DataTesting:
status_prediksi = PrediksiStatusKelulusan(data_uji)
cetak("Status Kelulusan Prediksi:", status_prediksi)
Manfaat Prediksi Status Kelulusan Mahasiswa
Prediksi status kelulusan mahasiswa menggunakan algoritma K-NN memiliki potensi manfaat yang besar bagi mahasiswa, perguruan tinggi, dan stakeholder lainnya. Dengan pemahaman yang lebih baik tentang faktor-faktor yang memengaruhi kelulusan, tindakan preventif dapat diambil lebih awal untuk membantu mahasiswa yang berisiko tinggi drop out. Selain itu, institusi pendidikan dapat meningkatkan efisiensi program pendidikan mereka dan memberikan dukungan tambahan kepada mahasiswa yang membutuhkannya. Ini semua bertujuan untuk membantu mahasiswa mencapai tujuan pendidikan mereka dengan lebih baik.

Posted on September 20, 2023, in Data mining and tagged Algoritma K-Nearest Neighbor, analisis data, Data mining, Drop Out, Indeks Prestasi Sementara, Jumlah SKS, Klasifikasi Mahasiswa, machine learning, Model Prediktif, Pendidikan Tinggi, Prediksi Kelulusan, Status Pekerjaan, Status Pernikahan. Bookmark the permalink. Leave a comment.








































Leave a comment
Comments 0