Klasterisasi Sampah pada Kota-kota di Indonesia Menggunakan Metode K-Means dan K-Medoids
Krisis sampah adalah masalah serius yang dihadapi oleh banyak kota di seluruh dunia, termasuk di Indonesia. Dengan pertumbuhan populasi dan urbanisasi yang pesat, manajemen sampah yang efisien menjadi semakin penting. Salah satu langkah awal dalam meningkatkan manajemen sampah adalah memahami pola dan karakteristik sampah di berbagai kota. Dalam artikel ini, akan dijelaskan bagaimana metode klasterisasi, khususnya K-Means dan K-Medoids, dapat digunakan untuk mengelompokkan data sampah dari 287 kota di Indonesia berdasarkan komposisinya.

Data Sampah di Indonesia
Data sampah yang kami gunakan dalam analisis ini mencakup 287 kota di seluruh Indonesia. Setiap data kota terdiri dari tiga atribut utama yang merupakan persentase komposisi sampah:
- Persentase Sampah Organik: Bagian dari sampah yang berasal dari bahan-bahan organik seperti sisa makanan, daun, dan bahan-bahan alami lainnya.
- Persentase Sampah Non-Organik: Bagian dari sampah yang terdiri dari bahan-bahan non-organik seperti plastik, kertas, logam, dan kaca.
- Persentase Sampah Lain-lain: Bagian dari sampah yang tidak termasuk dalam dua kategori di atas, misalnya, barang-barang elektronik, tekstil, dan limbah berbahaya.
Total persentase sampah dari ketiga kategori tersebut selalu sama, yaitu 100%.
Klasterisasi Data Menggunakan K-Means dan K-Medoids
Klasterisasi adalah salah satu teknik dalam analisis data yang memungkinkan kita untuk mengelompokkan data ke dalam kelompok-kelompok yang serupa berdasarkan karakteristik tertentu. Dalam kasus ini, kami akan menggunakan dua metode klasterisasi yang umum digunakan, yaitu K-Means dan K-Medoids, untuk mengelompokkan data sampah kota-kota di Indonesia.
1. K-Means
K-Means adalah metode klasterisasi yang berusaha membagi data ke dalam kelompok (kluster) berdasarkan kedekatan dengan pusat kluster tertentu. Dalam konteks ini, kita akan menggunakan K-Means untuk mengelompokkan kota-kota berdasarkan komposisi sampah organik, non-organik, dan lain-lain. Setelah pengelompokan selesai, kita dapat memahami karakteristik kelompok-kelompok ini, yang dapat membantu dalam perencanaan manajemen sampah yang lebih efisien.

2. K-Medoids
K-Medoids, juga dikenal sebagai PAM (Partitioning Around Medoids), adalah metode klasterisasi yang mirip dengan K-Means, tetapi pusat klusternya diwakili oleh medoid (titik data yang paling dekat dengan pusat kluster). K-Medoids memiliki keunggulan dalam menangani outliers dan data yang tidak terdistribusi normal. Dalam analisis ini, K-Medoids dapat membantu mengelompokkan kota-kota berdasarkan persentase sampah dengan lebih baik jika data memiliki pencilan (outliers).

Berikut ini adalah pseudocode untuk kasus pengklasteran data sampah kota-kota di Indonesia menggunakan metode K-Means dan K-Medoids:
# Inisialisasi data
DataSampah = [] # Data sampah dari 287 kota di Indonesia
K = 3 # Jumlah kluster yang akan dibentuk
# Fungsi untuk menghitung jarak antara dua data
function HitungJarak(data1, data2):
jarak = 0
for i from 1 to jumlah_atribut:
jarak += (data1[i] - data2[i])^2
return akar_kuadrat(jarak)
# Fungsi untuk menginisialisasi pusat-pusat awal kluster
function InisialisasiPusatKluster(data, K):
pusat_kluster = [] # Pusat kluster
ambil K titik awal secara acak dari data dan tambahkan ke pusat_kluster
return pusat_kluster
# Fungsi untuk mengelompokkan data ke dalam kluster
function KelompokkanData(data, pusat_kluster):
kluster = {} # Dicatat kluster mana setiap data masuk
untuk setiap data_sampah in data:
jarak_terdekat = tak_terhingga
untuk setiap pusat in pusat_kluster:
jarak = HitungJarak(data_sampah, pusat)
jika jarak < jarak_terdekat:
jarak_terdekat = jarak
kluster[data_sampah] = pusat
return kluster
# Fungsi untuk menghitung pusat baru dari kluster
function HitungPusatBaru(kluster):
pusat_baru = []
untuk setiap kluster_k in kluster:
data_dalam_kluster = semua data dalam kluster_k
pusat_baru_k = rata-rata(data_dalam_kluster)
tambahkan pusat_baru_k ke pusat_baru
return pusat_baru
# Main program
Baca DataSampah dari sumber data
Inisialisasi pusat-pusat awal kluster secara acak
Iterasi hingga konvergensi:
Kelompokkan data ke dalam kluster
Hitung pusat baru dari kluster
jika pusat baru sama dengan pusat sebelumnya, berhenti iterasi
Cetak hasil klasterisasi


Manfaat Analisis Klasterisasi Sampah
- Perencanaan Manajemen Sampah: Dengan memahami kelompok-kelompok kota yang memiliki karakteristik komposisi sampah yang serupa, pemerintah daerah dapat merancang strategi manajemen sampah yang lebih tepat sasaran. Ini termasuk pemilihan jenis pengelolaan sampah yang sesuai dengan karakteristik setiap kelompok.
- Pengurangan Dampak Lingkungan: Dengan memahami komposisi sampah secara lebih baik, upaya dapat diarahkan untuk mengurangi dampak lingkungan yang disebabkan oleh jenis sampah tertentu. Misalnya, pengurangan penggunaan plastik dapat menjadi fokus jika komposisi sampah non-organik yang tinggi didominasi oleh plastik.
- Efisiensi Sumber Daya: Analisis klasterisasi dapat membantu dalam alokasi sumber daya yang lebih efisien untuk pengelolaan sampah, termasuk anggaran, tenaga kerja, dan infrastruktur yang diperlukan.
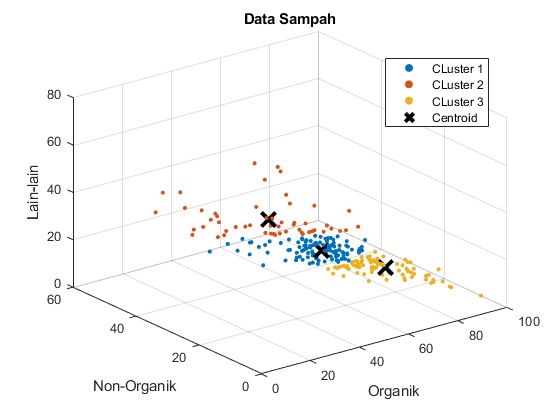
Pengolahan data dan analisis klasterisasi dapat menjadi alat yang sangat berguna dalam upaya meningkatkan manajemen sampah di Indonesia. Dengan memahami pola komposisi sampah berdasarkan kota-kota, langkah-langkah yang lebih tepat dapat diambil untuk mengurangi dampak lingkungan dan meningkatkan efisiensi pengelolaan sampah. Metode K-Means dan K-Medoids adalah salah satu cara yang efektif untuk melakukan analisis ini dan membantu memandu langkah-langkah ke depan dalam manajemen sampah yang berkelanjutan.
Posted on September 20, 2023, in Data mining. Bookmark the permalink. Leave a comment.








































Leave a comment
Comments 0