
Algoritma K-means Clustering dan Naive Bayes Classifier untuk Pengenalan Pola Tekstur
Pengenalan pola tekstur adalah salah satu aplikasi penting dalam pengolahan citra. Proses ini melibatkan identifikasi, klasifikasi, atau segmentasi dari pola tekstur dalam citra. Dalam artikel ini, akan dijelaskan penggunaan dua teknik klasifikasi yang umum digunakan, yaitu Algoritma K-means Clustering dan Naive Bayes Classifier, untuk pengenalan pola tekstur.

Pengenalan Pola Tekstur
Pola tekstur merujuk pada pola visual yang berulang dalam citra atau gambar. Contoh pola tekstur meliputi tekstur kayu, batu, daun, atau bahan tekstil. Tujuan dari pengenalan pola tekstur adalah mengklasifikasikan atau mengidentifikasi jenis-jenis tekstur ini dalam citra dengan akurasi tinggi.
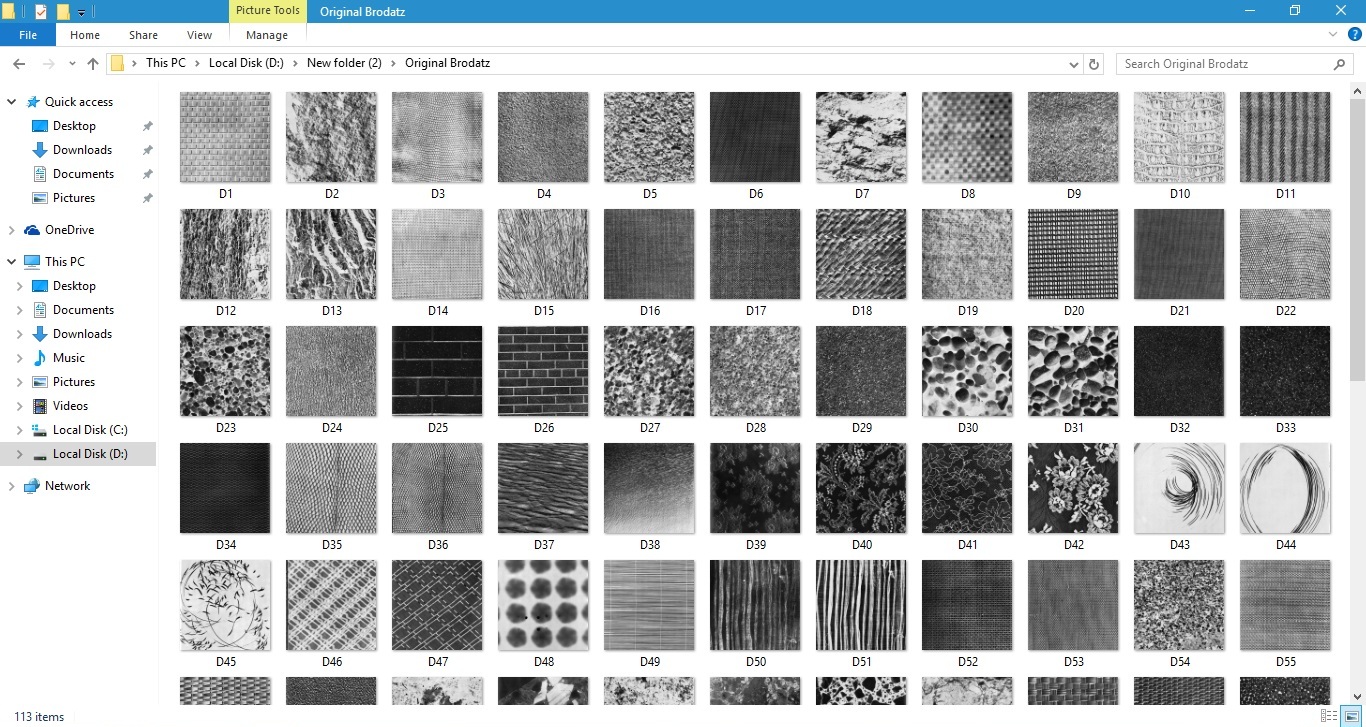
Algoritma K-means Clustering
Langkah-langkah K-means Clustering:
- Inisialisasi: Tentukan jumlah kluster (K) dalam dataset tekstur. Inisialisasi K titik acak sebagai pusat kluster awal.
- Penugasan: Atribusikan setiap sampel tekstur ke kluster terdekat berdasarkan jarak antara sampel dan pusat kluster.
- Pembaruan Pusat Kluster: Hitung ulang pusat kluster sebagai rata-rata dari semua sampel yang termasuk dalam kluster.
- Iterasi: Ulangi langkah-langkah 2 dan 3 hingga konvergensi atau hingga jumlah iterasi maksimum tercapai.
- Hasil: Hasil akhir adalah pusat kluster dan label kluster yang mengidentifikasi tekstur dalam citra.
Algoritma K-means Clustering dapat digunakan untuk mengelompokkan dan mengidentifikasi pola tekstur dalam citra dengan cara yang efektif.
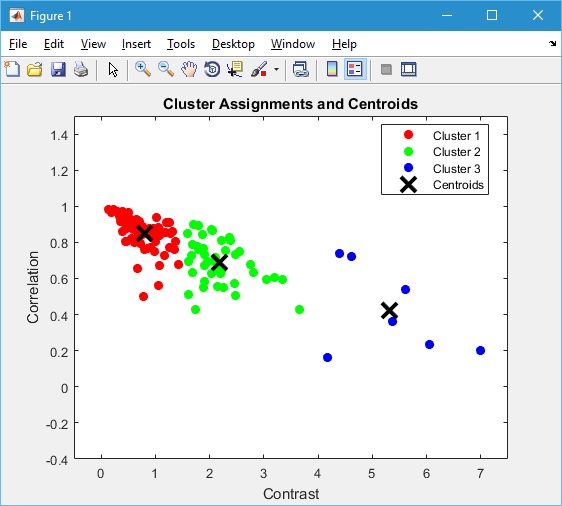
Naive Bayes Classifier
Naive Bayes Classifier adalah metode klasifikasi statistik yang berdasarkan teorema Bayes dengan asumsi “naive” bahwa atribut dalam dataset adalah independen satu sama lain. Ini adalah algoritma yang kuat dalam klasifikasi teks, tetapi juga dapat digunakan dalam pengenalan pola tekstur dengan representasi fitur yang sesuai.
Langkah-langkah Naive Bayes Classifier:
- Pelatihan Model: Selama tahap pelatihan, hitung probabilitas prior untuk setiap kelas dan probabilitas kondisional untuk setiap atribut dalam dataset tekstur.
- Klasifikasi: Selama tahap klasifikasi, gunakan teorema Bayes untuk menghitung probabilitas kelas yang paling mungkin untuk setiap sampel tekstur dalam citra berdasarkan atribut-atributnya.
- Hasil: Hasil akhir adalah label kelas yang sesuai dengan sampel tekstur.
Naive Bayes Classifier adalah algoritma klasifikasi yang cepat dan dapat memberikan hasil yang baik dalam pengenalan pola tekstur jika representasi fiturnya cocok.

Penggabungan K-means Clustering dan Naive Bayes
Dalam pengenalan pola tekstur, kita dapat menggabungkan K-means Clustering dengan Naive Bayes Classifier. Pertama, kita menggunakan K-means untuk mengelompokkan pola tekstur dalam citra menjadi kluster yang sesuai. Setelah itu, Naive Bayes digunakan untuk mengklasifikasikan kluster-kluster ini ke dalam kategori yang sesuai. Pendekatan ini dapat meningkatkan akurasi klasifikasi karena memungkinkan penyesuaian model Naive Bayes untuk setiap kluster secara terpisah.
Berikut ini pemrograman MATLAB mengenai Algoritma K-means Clustering dan Naive Bayes Classifier untuk pengenalan pola tekstur:
% Load dataset
fabricDataset = imageDatastore('dataset', 'IncludeSubfolders', true, 'LabelSource', 'foldernames');
% Pembagian dataset menjadi data pelatihan dan pengujian (80% pelatihan, 20% pengujian)
[trainingSet, testSet] = splitEachLabel(fabricDataset, 0.8, 'randomized');
% Ekstraksi fitur (contoh: fitur tekstur menggunakan GLCM)
trainingFeatures = [];
trainingLabels = trainingSet.Labels;
for i = 1:numel(trainingSet.Files)
img = readimage(trainingSet, i);
% Ekstraksi fitur GLCM
glcmFeatures = graycomatrix(rgb2gray(img), 'Offset', [0 1], 'Symmetric', true);
stats = graycoprops(glcmFeatures);
% Simpan fitur ke dalam matriks fitur pelatihan
trainingFeatures = [trainingFeatures; stats.Contrast, stats.Homogeneity, stats.Correlation, stats.Energy];
end
% Pelatihan model K-means
numClusters = 4;
[idx, centers] = kmeans(trainingFeatures, numClusters);
% Klasifikasi dengan Naive Bayes
nb = fitNaiveBayes(trainingFeatures, trainingLabels);
% Uji klasifikasi pada data pengujian
testFeatures = [];
testLabels = testSet.Labels;
for i = 1:numel(testSet.Files)
img = readimage(testSet, i);
% Ekstraksi fitur GLCM (Sama seperti yang dilakukan pada data pelatihan)
% Simpan fitur ke dalam matriks fitur pengujian
testFeatures = [testFeatures; stats.Contrast, stats.Homogeneity, stats.Correlation, stats.Energy];
end
predictedLabels = predict(nb, testFeatures);
% Evaluasi hasil
accuracy = sum(strcmp(predictedLabels, testLabels)) / numel(testLabels);
disp(['Akurasi Klasifikasi: ' num2str(accuracy)]);
Algoritma K-means Clustering dan Naive Bayes Classifier adalah dua teknik yang powerful untuk pengenalan pola tekstur dalam citra. Dengan kombinasi yang tepat dari representasi fitur, inisialisasi yang baik, dan pelatihan model yang tepat, maka dapat dihasilkan sistem pengenalan pola tekstur yang akurat dan berguna dalam berbagai aplikasi, seperti pengolahan citra medis, deteksi objek dalam citra, dan analisis citra satelit.
Source code beserta data lengkap pemrograman MATLAB di atas dapat diperoleh melalui halaman berikut ini: Source Code
Posted on September 7, 2023, in Pengenalan Pola and tagged glcm, K-Means Clustering, Klasifikasi Pola, Naive Bayes Classifier, Pengenalan Pola Tekstur, Penggabungan Algoritma, pengolahan citra, Representasi Fitur, Teknik Klasifikasi. Bookmark the permalink. Leave a comment.








































Leave a comment
Comments 0