
Klasifikasi Daun Jeruk Menggunakan Algoritma Support Vector Machine (SVM)
Support Vector Machine (SVM) adalah algoritma pembelajaran yang digunakan untuk klasifikasi dan regresi. Tujuannya adalah menemukan garis atau hiperplane terbaik yang memisahkan dua kelas data dengan margin maksimal di antara kelas-kelas tersebut. Margin adalah jarak antara garis/hyperplane dan titik-titik terdekat dari masing-masing kelas. SVM mencari titik-titik penting yang disebut vektor pendukung (support vectors) yang berada di sekitar garis/hyperplane pembatas.
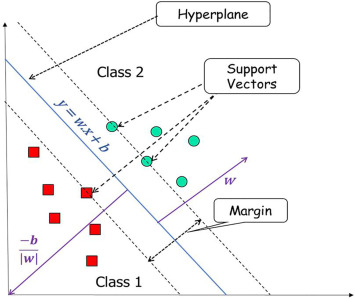
Bagaimana SVM Bekerja:
- Pemisahan dengan Margin Maksimal: SVM mencari garis/hyperplane yang memiliki margin maksimal di antara kelas data. Margin ini didefinisikan sebagai jarak terdekat antara garis/hyperplane dan data dari setiap kelas.
- Vektor Pendukung: SVM hanya memperhatikan titik-titik penting di sekitar garis/hyperplane, yaitu vektor pendukung. Ini adalah data yang berada paling dekat dengan garis/hyperplane pembatas. Mereka mempengaruhi posisi garis/hyperplane.
- Transformasi ke Ruang Fitur Lebih Tinggi (Kernel Trick): Jika data tidak dapat dipisahkan dengan baik secara linear, SVM dapat mentransformasi data ke ruang fitur yang lebih tinggi menggunakan fungsi kernel. Ini memungkinkan pencarian garis/hyperplane yang dapat memisahkan data tersebut di ruang fitur yang lebih kompleks.
- Penentuan Kelas Baru: Setelah pelatihan, SVM dapat digunakan untuk mengklasifikasikan data baru dengan memeriksa di mana sisi garis/hyperplane data baru berada. Apakah berada di sisi satu kelas atau yang lainnya.
Kelebihan SVM:
- Cocok untuk data dengan dimensi tinggi.
- Efektif dalam kasus di mana kelas tidak seimbang.
- Mampu mengatasi masalah non-linear melalui fungsi kernel.
Keterbatasan SVM:
- Memerlukan tuning parameter untuk mengoptimalkan kinerja.
- Komputasi bisa menjadi mahal pada dataset yang sangat besar.
- Pilihan fungsi kernel yang salah dapat menghasilkan hasil yang buruk.
SVM adalah algoritma yang handal untuk klasifikasi, terutama ketika terdapat dua kelas yang dapat dipisahkan dengan jelas atau ketika data dapat diubah ke dalam ruang fitur yang lebih tinggi.

1. Pendahuluan
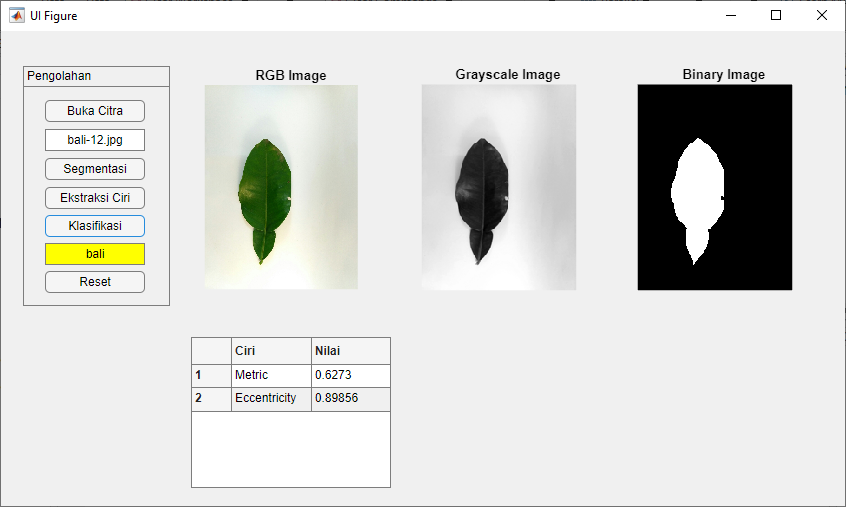
Penelitian ini bertujuan untuk mengimplementasikan pengolahan citra dan algoritma Support Vector Machine (SVM) dalam klasifikasi daun jeruk bali dan daun jeruk purut. Klasifikasi ini penting untuk aplikasi dalam bidang pertanian dan ilmu pangan. Proses pengolahan citra meliputi resizing, konversi citra rgb menjadi grayscale, segmentasi menggunakan algoritma k-means clustering, ekstraksi ciri dengan parameter metric dan eccentricity, serta klasifikasi menggunakan SVM.
2. Metode
2.1 Pengolahan Awal Citra
- Citra-citra daun jeruk diambil dan diawali dengan tahap resizing untuk memastikan ukuran citra yang konsisten.
- Citra rgb kemudian dikonversi menjadi citra grayscale untuk mengurangi dimensi citra dan mempertahankan informasi yang penting.
2.2 Segmentasi Menggunakan K-means Clustering
- Algoritma k-means clustering digunakan untuk membagi citra menjadi beberapa kelompok atau kluster.
- Pada penelitian ini, penggunaan k-means clustering difokuskan pada segmentasi daun jeruk dari background.
2.3 Ekstraksi Ciri
- Dua parameter ekstraksi ciri digunakan: metric dan eccentricity.
- Metric adalah ukuran perbandingan panjang dan lebar daun jeruk.
- Eccentricity mengukur sejauh mana bentuk daun jeruk dari lingkaran sempurna.
2.4 Klasifikasi dengan Algoritma Support Vector Machine (SVM)
- SVM digunakan sebagai algoritma klasifikasi.
- Fitur-fitur hasil ekstraksi digunakan sebagai input untuk SVM.
- Model SVM dilatih menggunakan data latihan.
3. Hasil
- Akurasi pelatihan yang dihasilkan adalah sebesar 95%.
- Pada tahap pengujian, akurasi yang dicapai mencapai 100%, menunjukkan kemampuan model dalam mengklasifikasikan daun jeruk bali dan daun jeruk purut.
4. Pembahasan
- Akurasi pelatihan yang tinggi menunjukkan bahwa model SVM mampu memahami karakteristik dan perbedaan antara kedua jenis daun jeruk.
- Akurasi pengujian yang sempurna menunjukkan bahwa model ini sangat efektif dalam mengklasifikasikan daun jeruk bali dan daun jeruk purut.
5. Kesimpulan
Penelitian ini mengimplementasikan proses pengolahan citra dan algoritma SVM untuk mengklasifikasikan daun jeruk bali dan daun jeruk purut. Hasilnya menunjukkan akurasi yang sangat baik, dengan akurasi pelatihan sebesar 95% dan akurasi pengujian 100%. Penggunaan metode pengolahan citra dan algoritma SVM ini dapat berkontribusi dalam pengembangan sistem pengenalan daun jeruk untuk aplikasi pertanian dan ilmu pangan.
6. Saran
Penelitian ini dapat ditingkatkan dengan mempertimbangkan penggunaan fitur-fitur ekstraksi lainnya serta penerapan teknik validasi silang untuk memastikan kehandalan model dalam mengklasifikasikan daun jeruk pada data yang belum pernah dilihat sebelumnya. Selain itu, penelitian lebih lanjut dapat melibatkan penggunaan dataset yang lebih besar dan variasi kondisi cahaya untuk menguji kestabilan model dalam berbagai situasi.
Tutorial lengkap penerapan pengolahan citra untuk Klasifikasi Daun Jeruk Menggunakan Algoritma Support Vector Machine (SVM) dapat dilihat pada video eksklusif berikut ini:
Posted on August 22, 2023, in Pengenalan Pola, Pengolahan Citra and tagged Algoritma Support Vector Machine (SVM), Daun Jeruk Bali, Daun Jeruk Purut, ekstraksi ciri, Klasifikasi Daun Jeruk, Konversi Citra RGB ke Grayscale, Parameter Metric dan Eccentricity, Penggunaan SVM dalam Klasifikasi Citra, pengolahan citra, Pengolahan Citra untuk Pertanian, Resizing Citra, Segmentasi dengan K-means Clustering, Tahap Klasifikasi SVM. Bookmark the permalink. Leave a comment.








































Leave a comment
Comments 0