
Algoritma C4.5 Berbasis Forward Selection dan Adaboost untuk Klasifikasi Nasabah
Dalam dunia perbankan, pengelolaan risiko kredit adalah salah satu aspek paling penting dalam menjaga stabilitas keuangan institusi. Salah satu cara untuk mengelola risiko ini adalah dengan menggunakan teknik-teknik pemodelan klasifikasi untuk memprediksi apakah seorang nasabah akan membayar pinjaman mereka tepat waktu (lancar) atau tidak (tidak lancar). Dalam artikel ini, akan dibahas penggunaan algoritma C4.5, C4.5 dengan Forward Selection, dan C4.5 dengan Forward Selection yang ditingkatkan menggunakan Adaboost untuk melakukan klasifikasi nasabah.

Algoritma C4.5
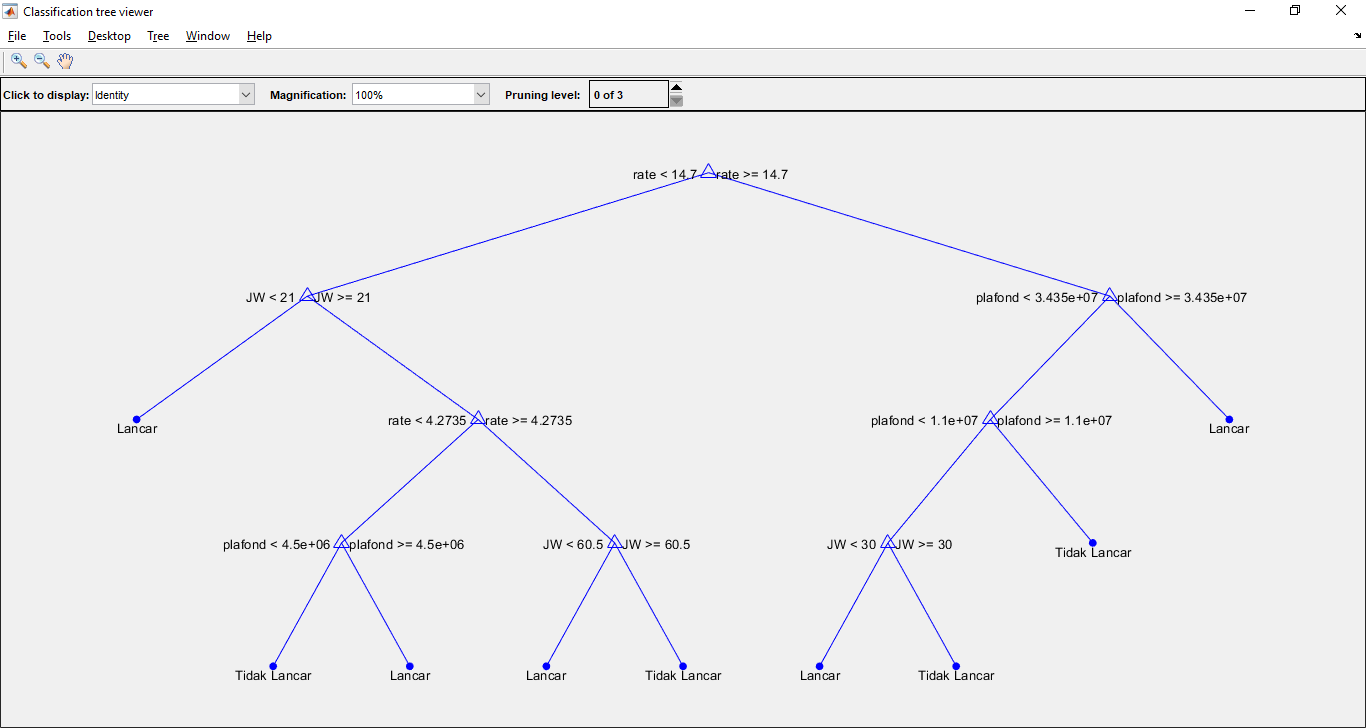
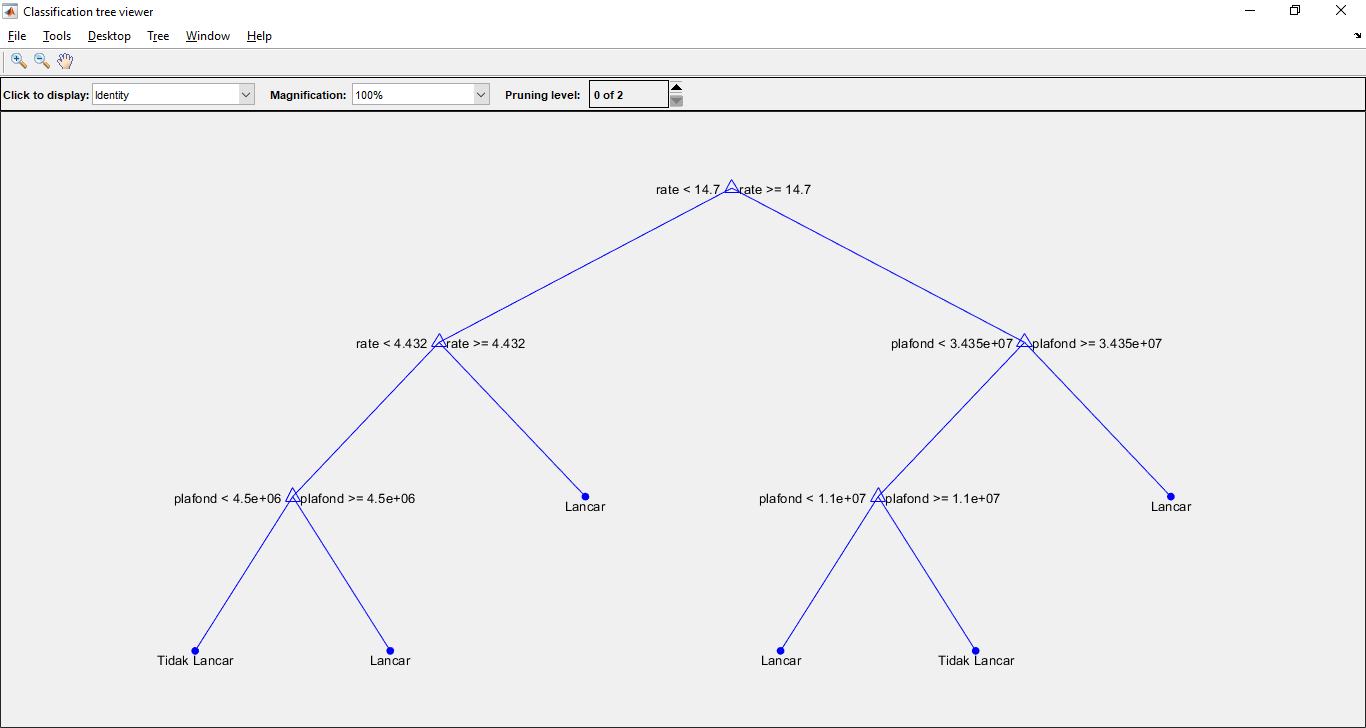
C4.5 adalah salah satu algoritma pembelajaran mesin berbasis pohon keputusan yang sangat populer. Algoritma ini digunakan untuk membangun pohon keputusan yang dapat digunakan untuk klasifikasi berdasarkan fitur-fitur masukan. Pohon keputusan ini dibangun dengan membagi data berdasarkan fitur-fitur tersebut secara rekursif hingga mencapai tingkat ketidakmurnian tertentu.
Forward Selection
Forward Selection adalah salah satu teknik seleksi fitur yang digunakan untuk memilih subset fitur-fitur yang paling relevan dalam memprediksi kategori nasabah. Teknik ini dimulai dengan satu fitur dan secara bertahap menambahkan fitur-fitur lainnya berdasarkan kontribusinya terhadap model klasifikasi.
Adaboost
Adaboost adalah algoritma ensemble learning yang digunakan untuk meningkatkan kinerja model klasifikasi dengan memberikan bobot yang lebih tinggi pada contoh-contoh yang salah diklasifikasikan pada iterasi sebelumnya. Ini memungkinkan model untuk fokus lebih pada contoh yang sulit diklasifikasikan.
Implementasi Algoritma
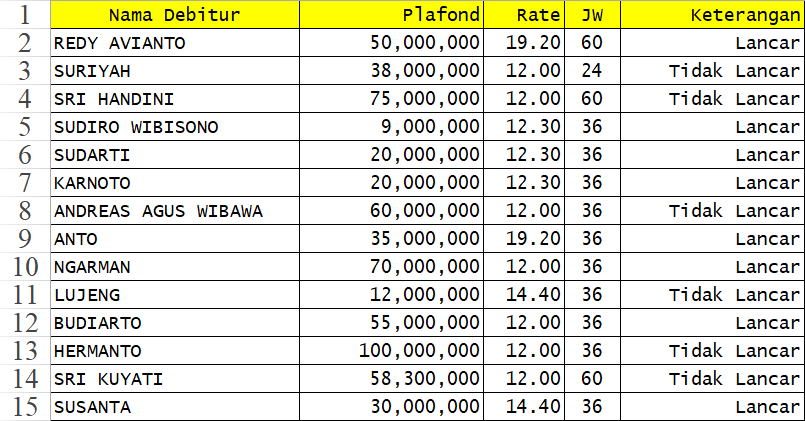
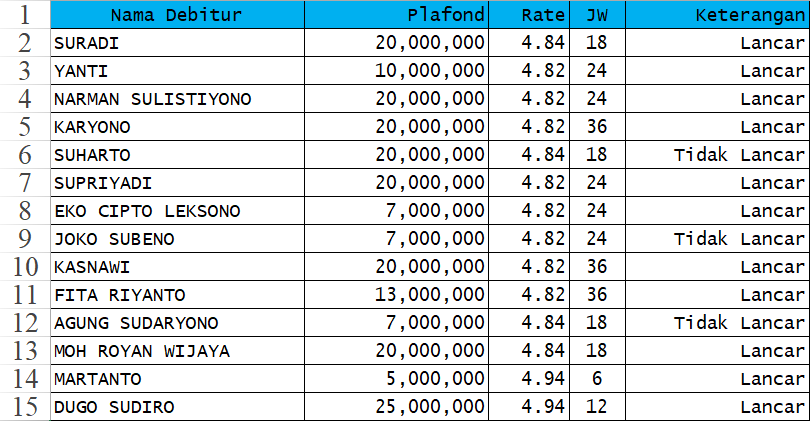
Dalam kasus ini, akan diterapkan algoritma C4.5, C4.5 dengan Forward Selection, dan C4.5 dengan Forward Selection yang ditingkatkan menggunakan Adaboost untuk melakukan klasifikasi nasabah berdasarkan tiga fitur masukan, yaitu:
- Plafond Pinjaman: Jumlah maksimum pinjaman yang diajukan oleh nasabah.
- Rate: Tingkat bunga yang berlaku untuk pinjaman.
- Jangka Waktu Pinjaman: Jumlah bulan yang dibutuhkan untuk melunasi pinjaman.
Hasil keluaran yang ingin diprediksi adalah kategori nasabah, yaitu “Lancar” atau “Tidak Lancar” dalam pembayaran pinjaman.
Langkah-langkah Pengolahan Data
- Pengumpulan Data: Data nasabah yang mencakup fitur-fitur masukan dan kategori keluaran dikumpulkan dari berbagai sumber.
- Preprocessing Data: Data dianalisis dan dibersihkan dari nilai-nilai yang hilang atau tidak valid. Selain itu, dapat dilakukan normalisasi atau transformasi pada fitur-fitur masukan jika diperlukan.
- Pembagian Data: Data dibagi menjadi dua subset, yaitu data pelatihan (training data) dan data pengujian (testing data).
- Pelatihan Model C4.5: Model C4.5 pertama kali dilatih menggunakan data pelatihan untuk membangun pohon keputusan.
- Seleksi Fitur Forward Selection: Forward Selection digunakan untuk memilih subset fitur-fitur yang paling relevan dari data pelatihan.
- Peningkatan Model dengan Adaboost: Adaboost digunakan untuk meningkatkan model C4.5 dengan memberikan bobot pada contoh-contoh yang salah diklasifikasikan.
- Evaluasi Model: Model yang telah ditingkatkan dievaluasi menggunakan data pengujian untuk mengukur kinerjanya dalam klasifikasi nasabah.
Pseucode
Berikut ini adalah pseudocode untuk kasus klasifikasi nasabah menggunakan algoritma C4.5 berbasis Forward Selection dan Adaboost:
# Import library yang dibutuhkan
import numpy as np
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import AdaBoostClassifier
from sklearn.metrics import accuracy_score, precision_score, recall_score
# Persiapan data pelatihan dan pengujian
X_train, y_train = load_training_data() # Load data pelatihan
X_test, y_test = load_testing_data() # Load data pengujian
# Inisialisasi model C4.5
c45_classifier = DecisionTreeClassifier()
# Inisialisasi model Adaboost dengan C4.5 sebagai base estimator
adaboost_classifier = AdaBoostClassifier(base_estimator=c45_classifier)
# Melatih model C4.5
c45_classifier.fit(X_train, y_train)
# Melakukan prediksi dengan model C4.5
c45_predictions = c45_classifier.predict(X_test)
# Mengukur kinerja model C4.5
c45_accuracy = accuracy_score(y_test, c45_predictions)
c45_precision = precision_score(y_test, c45_predictions)
c45_recall = recall_score(y_test, c45_predictions)
# Inisialisasi model C4.5+Forward Selection
selected_features = forward_selection(X_train, y_train) # Implementasi Forward Selection
c45_fs_classifier = DecisionTreeClassifier()
# Melatih model C4.5+Forward Selection hanya pada fitur terpilih
c45_fs_classifier.fit(X_train[:, selected_features], y_train)
# Melakukan prediksi dengan model C4.5+Forward Selection
c45_fs_predictions = c45_fs_classifier.predict(X_test[:, selected_features])
# Mengukur kinerja model C4.5+Forward Selection
c45_fs_accuracy = accuracy_score(y_test, c45_fs_predictions)
c45_fs_precision = precision_score(y_test, c45_fs_predictions)
c45_fs_recall = recall_score(y_test, c45_fs_predictions)
# Inisialisasi model C4.5+Forward Selection+Adaboost
c45_fs_adaboost_classifier = AdaBoostClassifier(base_estimator=c45_fs_classifier)
# Melatih model C4.5+Forward Selection+Adaboost
c45_fs_adaboost_classifier.fit(X_train[:, selected_features], y_train)
# Melakukan prediksi dengan model C4.5+Forward Selection+Adaboost
c45_fs_adaboost_predictions = c45_fs_adaboost_classifier.predict(X_test[:, selected_features])
# Mengukur kinerja model C4.5+Forward Selection+Adaboost
c45_fs_adaboost_accuracy = accuracy_score(y_test, c45_fs_adaboost_predictions)
c45_fs_adaboost_precision = precision_score(y_test, c45_fs_adaboost_predictions)
c45_fs_adaboost_recall = recall_score(y_test, c45_fs_adaboost_predictions)
# Menampilkan hasil kinerja masing-masing model
print("Kinerja Model C4.5:")
print("Akurasi:", c45_accuracy)
print("Presisi:", c45_precision)
print("Recall:", c45_recall)
print("Kinerja Model C4.5+Forward Selection:")
print("Akurasi:", c45_fs_accuracy)
print("Presisi:", c45_fs_precision)
print("Recall:", c45_fs_recall)
print("Kinerja Model C4.5+Forward Selection+Adaboost:")
print("Akurasi:", c45_fs_adaboost_accuracy)
print("Presisi:", c45_fs_adaboost_precision)
print("Recall:", c45_fs_adaboost_recall)
Keuntungan dan Manfaat
- Akurasi Tinggi: Penggabungan C4.5, Forward Selection, dan Adaboost dapat meningkatkan akurasi prediksi klasifikasi nasabah, yang memungkinkan bank untuk lebih akurat menilai risiko kredit.
- Pemahaman Lebih Baik: Pohon keputusan yang dihasilkan oleh C4.5 dapat membantu dalam pemahaman mengapa nasabah diklasifikasikan sebagai lancar atau tidak lancar.
- Efisiensi Operasional: Dengan menggunakan algoritma ini, bank dapat mengotomatisasi proses pengambilan keputusan terkait kredit, menghemat waktu dan sumber daya.

Dalam dunia perbankan, penggunaan algoritma C4.5 berbasis Forward Selection dan Adaboost untuk klasifikasi nasabah dapat membantu bank dalam mengelola risiko kredit dengan lebih baik. Dengan memanfaatkan fitur-fitur masukan seperti plafond pinjaman, rate, dan jangka waktu pinjaman, algoritma ini dapat memberikan prediksi yang lebih akurat tentang apakah seorang nasabah akan membayar pinjaman tepat waktu atau tidak. Hal ini dapat membantu bank dalam mengambil keputusan yang lebih baik dalam pemberian pinjaman dan pengelolaan risiko kredit secara keseluruhan.
Posted on September 21, 2023, in Data mining and tagged Adaboost, Algoritma C4.5, Bank, Decision Tree, Efisiensi Operasional, Forward Selection, Jangka Waktu Pinjaman, Klasifikasi Nasabah, Manajemen Risiko, Normalisasi Data, Pengambilan Keputusan, Pengelolaan Risiko Kredit, Plafond Pinjaman, Pohon Keputusan, Prediksi Kredit, Tingkat Bunga (Rate). Bookmark the permalink. Leave a comment.








































Leave a comment
Comments 0